Ich bin gerade verstärkt in meinem Lieblingstool opencode unterwegs. Zuletzt habe ich mich tiefer mit Subagents beschäftigt und wie man die parallel und sequentiell einsetzt. Und daraus gleich ein Video gemacht. Wer sich also vom Erklärbär Rob zeigen lassen will, wie man das effektiv einsetzt, immer zu: https://youtu.be/5BqGA7wuRAM
Autor: ro
Softwareenwickler, Kaffegustateur und Philosoph
E-Technisch interessiert und ich fürhe ein gesundes soziales Leben mit den normalen 20 Kontakten
Was ist Intelligenz
Die Definition von Inelligenz war schon immer herausfordernd und ist abschließend nicht geklärt. Ich will dennoch einen Versuch starten. Da ich momentan viel mit KI spiele und parallel eine kleine NI beobachte, wie sie ihre Umwelt erfasst und Sprache erlernt, ziehe ich so meine Schlüsse. Auch OpenClaw hat mich zuletzt inspiriert.
Also was ist Intelligenz?
Ich würde sagen, das ist so: LLMs machen ja schon eine recht gute Figur. Es sind statistische, deterministische Automaten, die allerdings chaotisch reagieren. Und dennoch damiteine statistische Vorhersage über den wahrscheinlichsten Ausgang der Tokenfolge machent. Damit wirkt die Ausgabe zwar undeterministisch/zufällig aber intelligent. Dennoch gehört zu Intelligenz viel mehr. Nämlich Vision und Abstraktion. Als menschliche Intelligenz bin ich den ganzen Tag Reizen ausgesetzt. Mein neuronales Neztwerk läuft quasi pausenlos. Einige dieser Reize lösen bei mir ein Begehren aus, eine Vision, was ich haben will, oder wohin ich mich entwickeln will. Das ist ein Teil, den wir aktuell alleine haben. Das hat sicherlich auch mit Gefühlen zu tun.
Intelligenz ist also in der Rolle (mit der Vision) mehrere Vorhersagen zur Erreichung eines Ziels zu machen und die beste (wenigste Kosten, Zielmaximierung) herauszusuchen und umzusetzen.
Ablauf
Nehmen wir an, ich habe eine Banane gesehen und einen entsprechenden Bedarf. Dann mache ich eine Wegplanung und entdecke einen Graben zwischen mir und der Banane. Meine Vorhersage ist: Der Graben ist so tief, da fällst du hinein und bist tot. Weiter gibt es die Vorhersage: Wenn ich rechtzeitig springe, komme ich über den Graben oder ich lasse es, dann erreiche ich nichts. Das sind die Vorhersage in der Rolle „Ich will die Banane“. Damit (und der Vision der Selbsterhaltung) werde ich mich zu Laufen und Springen entscheiden und mein Ziel erreichen. Es könnte sich aber auch die Rolle geben, die sagt „bringe dich um“, dann wird die Vorhersage „Ohne Springen fällst du“ die bevorzugte sein.
Ja, etwas einfach. Aber das sind m. E. die Komponenten für intelligentes Handeln. Die Vision und die rollenbezogenen Vorhersagen aus der Erfahrung/Training. Es ist also das Zusammenspiel mehrerer Komponenten (Neuronaler Netze/Bereiche). Es kommen ja in aller Regel noch Dinge hinzu wie Angst oder eine Fehlerüberprüfung („Moment mal, kann das stimmen?“). Also weitere Gegenspieler, die alles Beeinflussen. Dies ist unabhängig davon, ob ich meine Vorhersage aus statistischer Auswertung habe oder ob ich durch Abstraktion und Anwendung mein Ergebnis habe. Jedoch ist diese Abstraktion des Problems das, was ein Transformer-Modell (LLM) bislang nicht kann.
Wie ich OpenEMS zum laufen brachte
Hier mal eher ein Notitzblatt/Reminder, wie man OpenEMS zum laufen bekommt, da die Anleitung bei denen eher so mau ist. Oder wie beim Matheprof. „Das steht doch im Skript“… „ja, irgendwie 22 Seiten davor in einem Nebensatz im dritten Absatz links…. und ohne Beispiel“. Ja also hier mal was ich tat:
Aufbau
Zunächst zum Aufbau von OpenEMS. Es gibt die Teile:
- Edge
- Backend
- UI
- Zeitreihendatenbank/Influxdb
Man muss sich das so vorstellen, dass es mehrere Edge-EMS gibt. Das sind die lauffähigen Instanzen, die vor Ort sind und die eigentliche Arbeit des Messens und Steuerns machen. Die Rapportieren an das Backend (z.b. Messdaten und Stati)
Das Backend macht die Koordiation und Authentifizierung (hier Metadata genannt) und schreibt die Messdaten in eine Zeitreihendatenbank – hier verwendent: Influxdb
Zeitreihendatenbank/Influxdb: Die speichert die Messdaten und vergisst unwichtige Details.
UI: Die Grafishe Oberfläche. Das UI ist in node geschrieben und kann sowohl Edge als auch Backend betreuen. Typischerweise wird es zusammen mit ZeitDB und Backend auf einem Server im Internet erreichbar gehostet. In der Backendversion sieht man das Backend und alle verbunden Edge-Instanzen und kann dort „rüberwechseln“. Dabei mus keine eigene UI-Instanz per Edge laufen.
Deploy
Ich wollte ein docker deployment machen, damit man die Version schnell hochhauen kann. Ohne große Veränderung am Hostsystem. Und mit Renovate (Dienst) dann immer Up2Date ist. Einfach ein Redeploy machen.
Um nun InfluxDB, Backend und UI gemeinsam zu starten, hat sich diese docker-compose.yml-Datei bewährt. (docker label :develop kann durch :latest ersetzt werden)
services:
openems_backend:
image: openems/backend:develop
container_name: openems_backend
hostname: openems_backend
restart: unless-stopped
volumes:
- openems-backend-conf:/var/opt/openems/config:rw
- openems-backend-data:/var/opt/openems/data:rw
ports:
- 8079:8079 # Apache-Felix
- 8081:8081 # Edge-Websocket
- 8082:8082 # UI-Websocket
openems-ui:
image: openems/ui-backend:develop
container_name: openems_ui
hostname: openems_ui
restart: unless-stopped
volumes:
- openems-ui-conf:/etc/nginx:rw
- openems-ui-log:/var/log/nginx:rw
environment:
- UI_WEBSOCKET=ws://<publichost>:8082
ports:
- 1080:80
- 1443:443
openems_influxdb:
image: influxdb:alpine
container_name: openems_influxdb
hostname: openems_influxdb
restart: unless-stopped
volumes:
- openems-influxdb:/var/lib/influxdb2:rw
ports:
- 8086:8086
volumes:
openems-backend-conf:
openems-backend-data:
openems-ui-conf:
openems-ui-log:
openems-influxdb:
Natürlich wird man im Produktiven dann z.B. nginx als Reverse-Proxy davor hauen oder anderweitig TLS aktivieren.
Befehle:
# starten mit
docker compose up (-d)
# stoppen
docker compose down
# restart
docker compose restart
# status
docker ps
# backend logs anschauen
docker logs openems_backend -f
# shell
docker exec -it openems_backend bashEinrichten InfluxDB
Nachdem gestartet wurde, muss das Passwort und der API-Key (Notieren) von Influxdb gesetzt werden:
docker exec openems_influxdb influx setup \
--username openems \
--password WKeuIhl0deIJjrjoY62M \
--org openems.io \
--bucket openems \
--force
docker exec openems_influxdb influx auth listNun laufen einige Sachen
- Influxdb und Webobefläche: http://publichost:8086 mit openems:WKeuIhl0deIJjrjoY62M
- Backend ist erreichbar als Apache felix: http://publichost:8079/system/console mit admin:admin
- Backend hat einen Websocket exponiert: ws://publichost:8081
- UI ist erreichbar via http://publichost:8086/ ohne auth (irgendwas eingeben)
Das Problem ist erst mal, dass das Backend in einen Fehler läuft. Was man einem nicht sagt, ist, dass man eine metadata.conf-Datei braucht. Oder für den Test halt nicht braucht.WARN [end.metadata.file.MetadataFile] [Metadata.File] Unable to read file [/var/opt/openems/metadata.json]: /var/opt/openems/metadata.json (No such file or directory)
Das löst man, indem man beim Backend den Dummy-Metadata-Service konfiguriert: Gehe auf das Apache Felix des Backends (http://publichost:8079/system/console ) und kille Metadata.File und Hinzufüge Metadata.Dummy (keine Konfig erforderlich) Wenn es so aussieht, geht’s erst mal:
Timedata.InfluxDB sollte in etwa so aussehen:
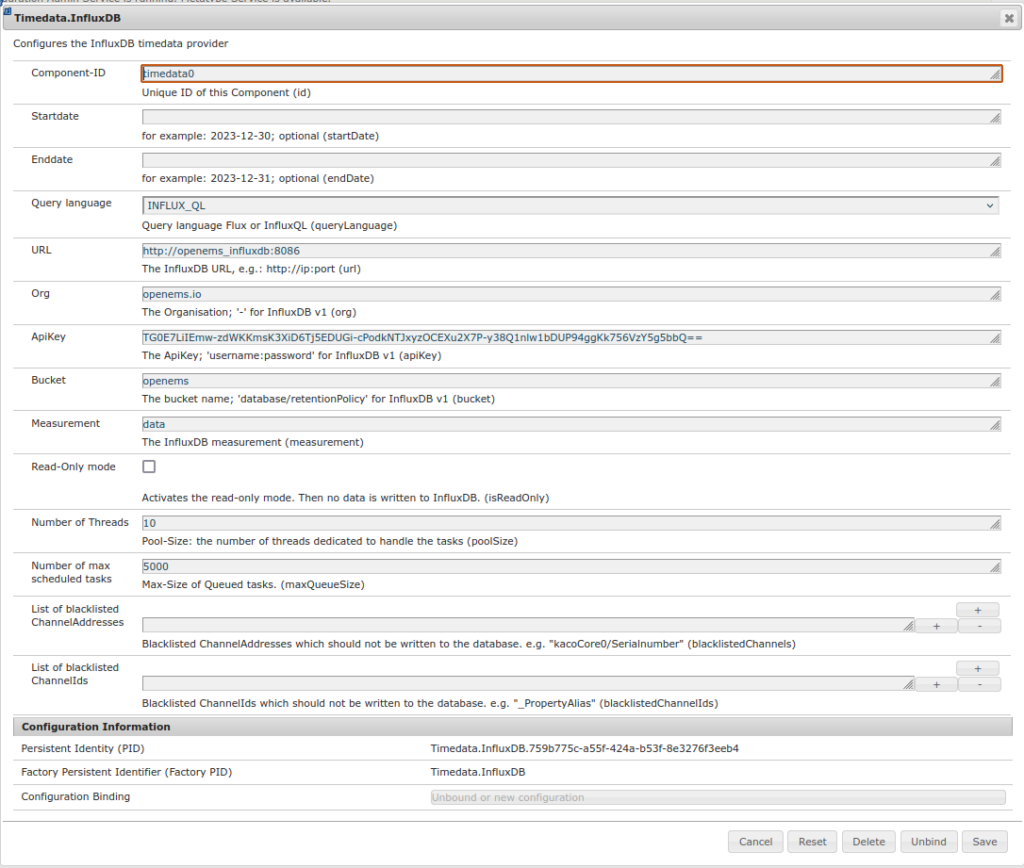
Der API-Key ist der, der weiter oben bei Einrichten InfluxDB ausgespuckt wurde. org und Bucket festlegen. Ansonsten kann man die influxdb Doker-Intern erreichen!
Zum vollständigen Glück fehlt noch ein wenig Konfig im Backend und eine Edge-Instanz und deren Konfig.
Edge
Um eine Edge-Instanz zu haben, habe ich mir ein Entwicklersystem eingerichtet und es lokal laufen lassen. Damit war ich dann zumindest mal auf einem anderen Host als da wo der Docker läuft. Macht es etwas realitätsnäher. Man kann die edge sicher auch als docker laufen lassen. Auf jeden Fall muss die irgendwie mit dem Backend verbunden werden und weiter Konfiguriert. Verbindung zum Backend gibt’s hier; nächstes Kapitel verweist auf weitere Konfigurationen, die in der Online-Doku sind, die man anwenden sollte auf der Edge.
Man geht also auf das Apache Felix der Edge-Instanz. Bei mir ist das (wegen Entwicklersystem) http://localhost:8080/system/console/configMgr PW: admin:admin
Hier Konfiguriere ich den Controller Api Backend wie folgt:
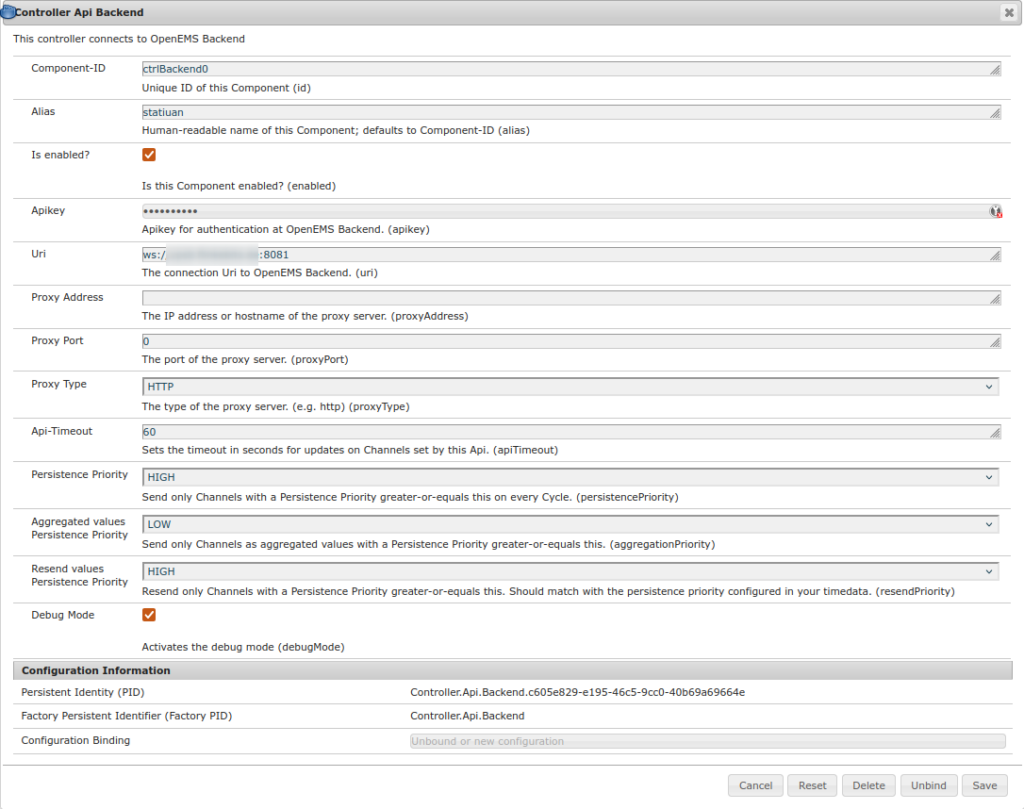
Wesentlich ist die WS-Url zu dem global auflösenden Namen des Backends. Wie durch Docker compose festgelegt ist es auf Port 8081. Da wir Metadata.Dummy einsetzen, ist der API-Key egal. Ebenso der alias.
Konfig des Backends und Edges
Edge braucht noch einige Komponenten, um ein wenig „was zu tun“.
Konfigurieren wie hier: https://openems.github.io/openems.io/openems/latest/gettingstarted.html#_configure_openems_edge
Test
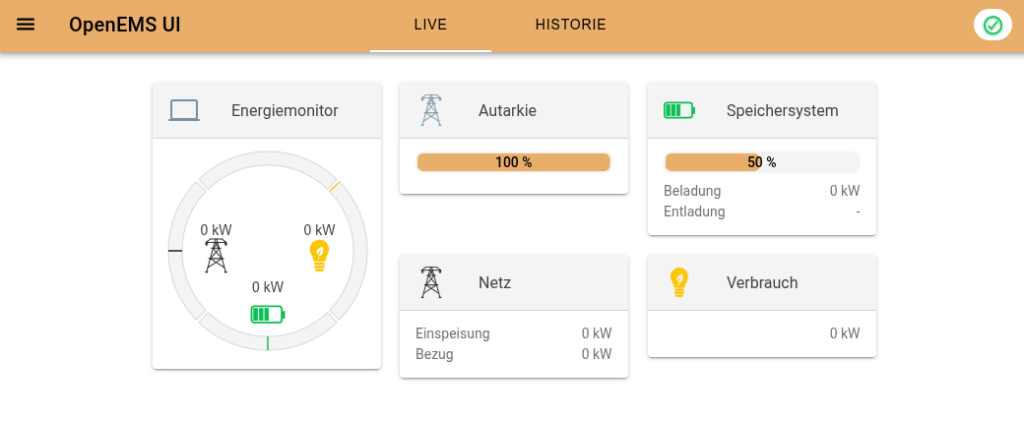
Nun kann man auf die UI gehen: http://publichost:8086/ Nutzername ist wie gesagt egal (weil Metadata.Dummy) und dort sollte nun die Edge-Instanz auftauchen, die man gestartet hat.
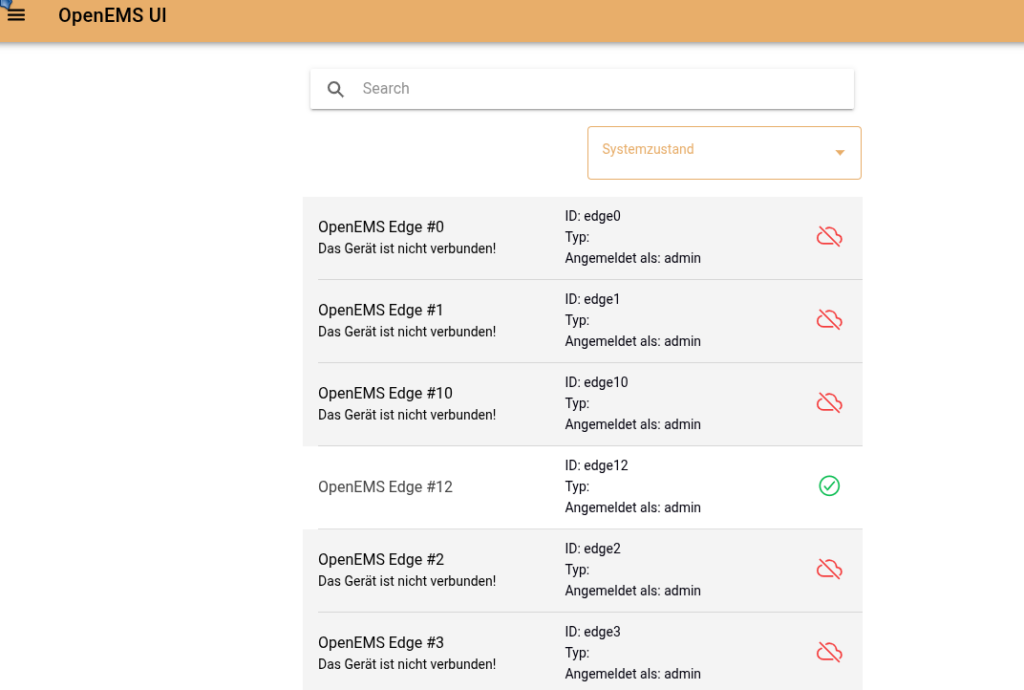
drinnen sieht es etwa so aus (je nach Simulation mehr)
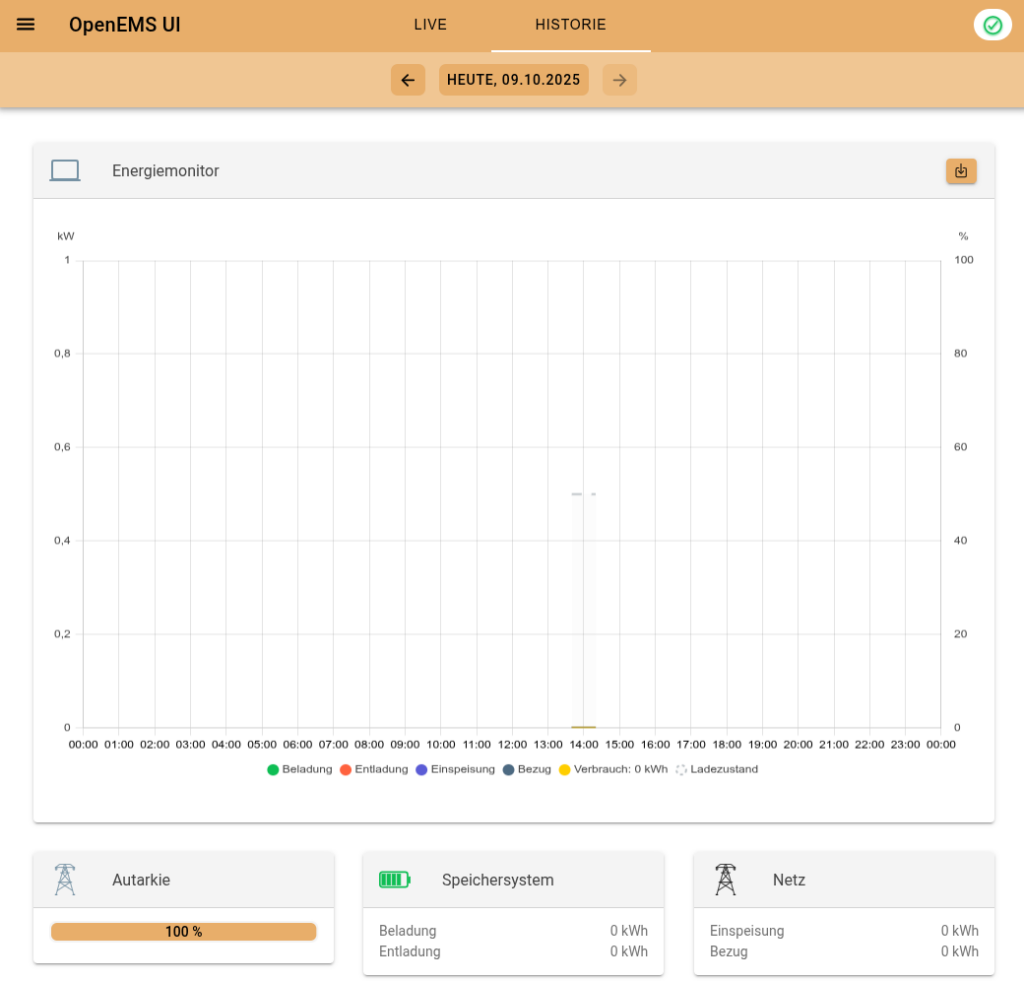
In die Historie kommt man auch (da man ja das Backend hat):
Wireguard auf einfach
Wireguard, dieses VPN kann einen ganz schön beschäftigen. Zunächst vermutet man die Funktionalität anders gelagert, ehe man später herausfindet, wie es ist und es korrekt macht. Um diesen Weg zu vereinfachen, habe ich mir gedacht, dass ich mal einige klärende Sätze los werde und meine paar Skripte dazu gebe, mit denen ich das Ganze Management ziemlich einfach gestaltet habe.
Wireguard das Wesen
Wireguard ist toll simpel und doch in der Konfiguration sehr komplex. Zumindest, wenn man unbedarft ran geht, versteht man erst mal nicht was eine gute Konfiguration ist und welche Randparameter einzuhalten sind.
Erkenntnis
Die Erkenntnisse dazu sind:
- Wireguard ist eine Punkt-zu-Punkt VPN-Verbindung. Das heißt, es werden keine Netze verbunden sondern immer nur zwei Interfaces miteinander.
- Daraus leitet sich die Folge ab, dass der Verkehr also über das einzurichtende Zwischennetz geroutet wird.
- Ein Paket wandert also von einem Netz durch den Forwarder in das VPN-Netz und auf der anderen Seite in das ferne Netz, wieder durch den Forwarder des VPN-Routers.
- Wireguard kann nur immer einen Gegner pro Interface und Port haben
- Man muss also viele kleine Netze anlegen und jeweils eigene Ports nutzen
- Es gibt Konfigs für Clients und für Server
- Die Schlüssel darin sind anitsymmetrisch darin verteilt (perfekt zur Automatisierung)
- Die IP-Adressen sind ebenfalls antisymmetrisch
- Andere Dinge sind gleich oder nur hier oder dort anzuwenden
Anwendungsfall
Ich beschränke mich hier auf den Anwendungsfall Netzkopplung mit einem zentralen Router. Sprich es gibt mehrere Clients und diese bringen entweder sich selbst oder zusätzlich ein ganzes Netz herein. Ab da funktioniert das Routing auch zwischen den Netzen (Voraussetzung sind allerdings gepflegte statische Routen auf dem Standardgateway der gekoppelten Netze = war immer so).
Skripte
Dieses wurde berücksichtigt, um die folgenden Skripte zu erstellen. Als einzigstes Ding muss man sich einen Namen ausdenken für den neuen Client. Und natürlich muss die dabei entstandene Client-Konfig auf den Client verbracht werden.
Die Skripte sind dazu gedacht, im /etc/wireguard-Verzeichnis zu residieren und dort lokal Änderungen zu machen und als root systemctl aufzurufen.
Als Infrastruktur kommt ein _-Verzeihnis mit. Darin sind die Vorlagedateien für die Server- und Client-Konfig drin mit Platzhalter. Das mk_-client.sh-Skript macht dann mit sed einen Such- und Ersetzenlauf. Weiterhin sind in diesem Verzeichnis .txt-Dateien, die die jeweils zuletzt vergebenene IP/Port enthält. Diese Dateien sind bei Bedarf/zu Beginn zu pflegen.
_/last-ip.txt
10.254.0.4Anpassen bei Bedarf – das 10er Netz scheint gut. Es wird immer 2 hochgezählt, da ja immer Point-to-Point zwei Adressen gebraucht werden.
_/last-port.txt
14264Hier wird der letzte Port gemerkt und weiter hochgezählt. alles uter 64k ist gut.
_/client.conf
[Interface]
# set address to next address
Address = :CLIENT_IP:/32
PrivateKey = :CLIENT_KEY:
#DNS = 8.8.8.8
[Peer]
PublicKey = :SERVER_PUB_KEY:
Endpoint = :SERVER_ADDRESS:::PORT:
PresharedKey = :PSK:
# Route only vpn trafic through vpn
AllowedIPs = 10.254.0.0/24, 192.168.88.0/24, 192.168.22.0/24
# Route ALL traffic through vpn
#AllowedIPs = 0.0.0.0/0
PersistentKeepalive = 21dsHier sind Platzhalter mit :PLH:-Notation drin, die beim Erzeugen ersetzt werden. Bei AllowedIPs kann der geneigte Admin all seine Netze hinzufügen. Da dieser Teil kopiert wird, müssen alle erstellten client.confs angepasst werden, wenn neue Netze hinzukommen. In diesem Fall sind es /24-Netze.
_/server.conf
[Interface]
Address = :SERVER_IP:/32
MTU = 1420
ListenPort = :PORT:
PrivateKey = :SERVER_KEY:
PostUp = /etc/wireguard/wg-iptables-updown.sh :IF_NAME: up
PostDown = /etc/wireguard/wg-iptables-updown.sh :IF_NAME: down
[Peer]
PublicKey = :CLIENT_PUB_KEY:
PresharedKey = :PSK:
AllowedIPs = :CLIENT_IP:/32Dies ist die Vorlage für neue Server-Konfigs. Interessant dabei, dass die eigene und Gegen-IP des VPN-Netzes /32-Adressen sind. Also genau je eine Adresse. Zudem ist hier der wg-iptables-updown.sh – Aufruf drin, der das Routing auf dem zentralen Router aktualisiert und entsprechende Forwarding-Regeln einfügt oder entfernt. Diese Datei ist auch mit dabei. Siehe hier:
wg-iptables-updown.sh
#!/bin/sh
iptables="/usr/sbin/iptables"
if [ -z "$1" ]; then
echo "No interface!"
echo "Usage: $0 [interface] [action]"
exit 0
fi
if [ -z "$2" ]; then
echo "No action!"
echo "Usage: $0 [interface] [action]"
echo "Actions:"
echo "* up"
echo "* down"
exit 0
elif [ "$2" = "up" ]; then
action="-A"
elif [ "$2" = "down" ]; then
action="-D"
else
echo "Unknown action!"
echo "Usage: $0 [interface] [action]"
echo "Actions:"
echo "* up"
echo "* down"
exit 0
fi
$iptables $action FORWARD -i $1 -j ACCEPT
$iptables $action FORWARD -o $1 -j ACCEPTHauptteil
Den Hauptteil bilden die zwei Skripte mk-client.sh und rm-client.sh
Damit wird ein neuer VPN-Entpunkt hinzugefügt bzw entfernt.
mk-client.sh
Einzig der Name für diese Verbindung wird als Parameter gebraucht. Es wird dafür ein öffentlicher und Privater Schlüssel und ein neues Geheimnis ausgewürfelt und in entsprechenden Dateien im ./clients/-Verzeichnis gespeichert. Von dort kann man die Dateien (eigentlich nur die .cofig) für den Client extrahieren und weitergeben. Die Server-.config wird im /etc/wireguard-Verzeichnis abgelegt und ist somit direkt verfügbar. Das wird auch gleich genutzt und wireguard damit konfiguriert. Sowohl die client- als auch die server-Konfig sind Kopien der Vorlagedateien. Die Platzhalter (wie z.B. Schlüssel und IPs) werden durch sed-Aufrufe ersetzt. So einfach.
Am Ende kommt noch eine Frage, ob man denn die Konfig gleich in systemd und beim Systemstart aktivieren möchte.
#!/bin/bash
VPN_HOST=vpn.flinkebits.de
if [ $# -eq 0 ]
then
echo "must pass a client name as an arg: mk-client.sh new-client"
else
umask 077
echo "Creating client config for: $1"
mkdir -p clients/$1
wg genkey | tee clients/$1/$1.priv | wg pubkey > clients/$1/$1.pub
CLIENT_KEY=$(cat clients/$1/$1.priv)
CLIENT_PUB_KEY=$(cat clients/$1/$1.pub)
infix=$(cat _/last-ip.txt | tr "." " " | awk '{print $4}')
ips="10.254.0."$(expr $infix + 1)
ipc="10.254.0."$(expr $infix + 2)
lastport=$(cat _/last-port.txt)
port=$(expr $lastport + 1)
wg genpsk > clients/$1/$1.psk
PSK=$(cat clients/$1/$1.psk)
wg genkey | tee clients/$1/server.priv | wg pubkey > clients/$1/server.pub
SERVER_KEY=$(cat clients/$1/server.priv)
SERVER_PUB_KEY=$(cat clients/$1/server.pub)
cat _/server.conf | sed -e 's|:PSK:|'"$PSK"'|' | sed -e 's/:SERVER_IP:/'"$ips"'/' | sed -e 's/:CLIENT_IP:/'"$ipc"'/' | sed -e 's|:SERVER_KEY:|'"$SERVER_KEY"'|' | sed -e 's|:CLIENT_PUB_KEY:|'"$CLIENT_PUB_KEY"'|' | sed -e 's|:PORT:|'"$port"'|' | sed -e 's|:IF_NAME:|'"wg-$1"'|' > wg-$1.conf
cat _/client.conf | sed -e 's|:PSK:|'"$PSK"'|' | sed -e 's/:CLIENT_IP:/'"$ipc"'/' | sed -e 's|:CLIENT_KEY:|'"$CLIENT_KEY"'|' | sed -e 's|:SERVER_PUB_KEY:|'"$SERVER_PUB_KEY"'|' | sed -e 's|:PORT:|'"$port"'|' | sed -e 's|:SERVER_ADDRESS:|'"$VPN_HOST"'|' > clients/$1/$1.conf
echo "Erzeuge in clients/$1 $1.priv, $1.pub, server.priv, server.pub"
echo "Erzeuge clients/$1/$1.conf"
echo "Erzeuge wg-$1.conf"
echo "Speichere zuletzt verwendete IP, Port: $ipc : $port"
echo $ipc > _/last-ip.txt
echo $port > _/last-port.txt
echo "Konfig fertig!"
read -p "Aktivieren von $1 in systemctl? (y/n) " yn
case $yn in
[yY] ) echo ok, we will proceed;
systemctl enable wg-quick@wg-$1.service
systemctl start wg-quick@wg-$1
;;
* ) echo exiting...;
exit;;
esac
firm-client.sh
Die rm-client macht es recht einfach. Fährt das interface ordentlich runter, entfernt es aus systemd und löscht die Dateien:
#!/bin/bash
if [ $# -eq 0 ]
then
echo "must pass a client name as an arg: $0 aclient"
else
wg-quick down wg-$1
systemctl stop wg-quick@wg-$1
systemctl disable wg-quick@wg-$1.service
rm -rfv "/etc/wireguard/clients/$1/"
rm -v "/etc/wireguard/wg-$1.conf"
fiGIT-Repo
Das Ganze könnt ihr auch in einem Git-Repo auf einmal herunterladen und in euer /etc/wireguard-Vz werfen. https://github.com/ChaosChemnitz/Wireguard-einfach
Lodgify per API abfragen
Seit einiger Zeit bin ich mit meiner Familie dabei, eine Ferienwohnung zu betreiben. Das ist eher aus der Not heraus geworden, denn die Gewerbeeinheit ließ sich sonst nicht vermieten. Ergo musste man halt mal selbst ran an die Sache.
Ich will hier gar nicht abschweifen in die Untiefen der Ferienwohnungen und deren Implikationen. Nur so viel: Ohne Buchungsportale geht heute quasi nix und wer nicht mindestens auf AirBnB und booking unterwegs ist, bekommt nichts vom Kuchen ab. Doch wie verwaltet man die mindestens zwei „Kanäle“? Man braucht einen „Channelmanager“. Davon gibt es in der echt recht korrupten Hoteleriebranche viele. Sie überbieten sich meist eher darin, ein möglichst großes Stück von deinem verdienten Geld mit abzugreifen – mit Prozenten etc.
Am Ende entscheidet man sich für irgendwas, was mit halbwegs normalen Kosten und Features wie dynamische Preise und (sowieso) Synchronisation der Kalender aufwartet. Bei uns ist das, wie auch immer, Lodgify geworden.
Aber jetzt kommts: Die bieten zwar einen Basistarif (der für uns die richtige Mischung ist), aber die echten Basisfeatures bieten sie halt da nicht an. Edit: Wundere mich gerade, warum überhaupt Kanäle buchbar angebunden sind??! Also was fehlt: Es gibt nicht mal eine absolute Basisübersicht über die Buchungen des aktuellen Monats und die Einnahmen. Dummerweise sollte man diese Daten haben, wenn man die lokalen Steuern bezahlen will. Aber dieses Feature gibt es auch nicht im Pro-Plan, sondern nur im Ultra-Plan. OKOK, ist wohl absolut ultra, dass ich mal so eine Übersicht als Tabelle benötige… nun ja.
Zum Glück aber gibt es ein Integrations-API. Damit konnte ich mit doch sehr überschaubarem Aufwand meine Buchungen abrufen. Hier mal mein Vorschlag, das in Python zu machen. Viel Spaß beim nachmachen:
Pythonimplementierung:
import requests
import pandas as pd
from datetime import datetime
# ggf installieren:
# pip install requests pandas openpyxl
# API-Konfiguration
API_KEY = "<bitte füllen>" # Ersetze mit deinem Lodgify API-Key
BASE_URL = "https://api.lodgify.com/v2/reservations/bookings"
# Zeitrahmen für die Abfrage (optional)
params = {
"size":100,
"includeExternal": True,
"stayFilter": "Historic",
"trash": False
}
# API-Anfrage mit korrektem X-ApiKey-Header
headers = {
"X-ApiKey": API_KEY,
"Accept-Language": "de",
"accept": "application/json"
}
try:
print("Starte API-Anfrage...")
response = requests.get(BASE_URL, headers=headers, params=params, timeout=10)
response.raise_for_status() # Löst HTTPError für 4xx/5xx Statuscodes aus
data = response.json()
# Prüfe, ob die Antwort die erwartete Struktur hat
if not isinstance(data, dict) or "items" not in data:
raise ValueError("Ungültige API-Antwort: JSON element 'items' nicht gefunden.")
except requests.exceptions.HTTPError as errh:
print(f"HTTP-Fehler: {errh}")
print(f"Statuscode: {response.status_code}")
print(f"Antwort: {response.text}")
exit(1)
except requests.exceptions.ConnectionError as errc:
print(f"Verbindungsfehler: {errc}")
exit(1)
except requests.exceptions.Timeout as errt:
print(f"Timeout-Fehler: {errt}")
exit(1)
except requests.exceptions.RequestException as err:
print(f"Anfragefehler: {err}")
exit(1)
except ValueError as ve:
print(f"Datenfehler: {ve}")
exit(1)
# Daten aufbereiten
bookings = []
for booking in data.get("items", []):
arrival = booking.get("arrival")
departure = booking.get("departure")
rooms = booking.get("rooms", [])
total_amount = booking.get("total_amount", 0)
guest = booking.get("guest")
# Anzahl der Tage berechnen
if arrival and departure:
try:
arrival_date = datetime.strptime(arrival, "%Y-%m-%d")
departure_date = datetime.strptime(departure, "%Y-%m-%d")
num_days = (departure_date - arrival_date).days
except ValueError:
num_days = 0
else:
num_days = 0
# Gast-Informationen aus dem ersten Zimmer extrahieren
adults = 0
children = 0
people = 0
if rooms:
guest_breakdown = rooms[0].get("guest_breakdown", {})
adults = guest_breakdown.get("adults", 0)
children = guest_breakdown.get("children", 0)
people = rooms[0].get("people", 0)
bookings.append({
"Buchungs-ID": booking.get("id"),
"Gastname": guest.get("name"),
"Startdatum": arrival,
"Enddatum": departure,
"Anzahl Tage": num_days,
"Anzahl Erwachsene": adults,
"Anzahl Kinder": children,
"Anzahl Personen": people,
"Einnahmen (€)": total_amount
})
# DataFrame erstellen
df = pd.DataFrame(bookings)
# In Excel-Datei speichern
output_file = "lodgify_buchungen.xlsx"
try:
df.to_excel(output_file, index=False, engine="openpyxl")
print(f"✅ Daten wurden erfolgreich in {output_file} gespeichert.")
except Exception as e:
print(f"❌ Fehler beim Speichern der Excel-Datei: {e}")
exit(1)Ergebnis ist eie XLS-Datei mit den Buchungen und Einnahmen
Warum ist Wasser blau
Warum sieht Wasser blau aus, wenn man durchschaut. Bzw. warum filtert es rot aus?
Eie hoch interessante Frage, vor allem, wenn man es genau nimmt mit den Details, also den Quanteneffekten, die die Valenzelektronen des Wassermoleküls haben.
Einfache Antwort
Die blaue Farbe des Wassers, die man sieht, wenn man durch klares Wasser schaut, hat mit der Art und Weise zu tun, wie Wasser Licht absorbiert und streut. Dies ist ein physikalisches Phänomen, das auf der Wechselwirkung von Licht mit den Molekülen des Wassers basiert.
- Absorption von Licht
Wasser absorbiert Licht nicht gleichmäßig über das gesamte sichtbare Spektrum. Es absorbiert Licht im roten, orangen und gelben Bereich des Spektrums stärker als Licht im blauen Bereich. Das bedeutet, dass die roten und gelben Wellenlängen des Lichts „herausgefiltert“ werden, während die blauen Wellenlängen weniger stark absorbiert werden und somit dominieren. Dies führt dazu, dass Wasser für das menschliche Auge blau erscheint.
- Streuung von Licht
Zusätzlich zur Absorption spielt auch die Streuung von Licht eine Rolle. Wenn Licht auf die Moleküle im Wasser trifft, wird es gestreut. Blaues Licht hat kürzere Wellenlängen und wird stärker gestreut als rotes Licht mit längeren Wellenlängen. Dies verstärkt den blauen Eindruck des Wassers.
- Tiefe des Wassers
Die blaue Farbe des Wassers wird deutlicher, je tiefer das Wasser ist. In flachen Gewässern oder in kleinen Mengen (z. B. in einem Glas) ist der Effekt oft nicht so stark sichtbar, da das Licht nicht genug Weg durch das Wasser zurücklegt, um die Absorption und Streuung deutlich zu machen.
- Zusätzliche Faktoren
Die Farbe des Wassers kann auch durch andere Faktoren beeinflusst werden, wie z. B. Schwebstoffe, Algen oder andere Verunreinigungen, die das Licht auf unterschiedliche Weise streuen oder absorbieren. In solchen Fällen kann das Wasser grünlich, braun oder sogar rot erscheinen.
Zusammengefasst: Wasser erscheint blau, weil es rotes Licht stärker absorbiert und blaues Licht weniger stark absorbiert und streut. Dieses Phänomen ist ein Ergebnis der physikalischen Eigenschaften von Wasser und der Wechselwirkung mit Licht.
Physikalische Details
Streuung und Absorption sind zwei unterschiedliche physikalische Prozesse, die beschreiben, wie Licht (oder andere elektromagnetische Wellen) mit Materie interagiert.
1. Streuung
- Definition: Streuung tritt auf, wenn Licht auf ein Objekt oder Molekül trifft und seine Richtung geändert wird, ohne dass es von der Materie „verschluckt“ wird. Das Licht wird also umgelenkt, bleibt aber in seiner Energie (Farbe) erhalten.
- Was passiert mit dem Licht?: Das Licht wird in verschiedene Richtungen verteilt, abhängig von der Größe und Struktur der Streuungspartikel.
- Beispiele:
- Rayleigh-Streuung: Blauer Himmel, der abends orange wird.
- Mie-Streuung: Tritt bei größeren Partikeln auf, z. B. bei Nebel oder Wolken, und streut Licht gleichmäßiger in alle Richtungen.
- Wichtig: Bei der Streuung wird das Licht nicht „verbraucht“, sondern nur umgelenkt.
2. Absorption
- Definition: Absorption tritt auf, wenn Licht von einem Material aufgenommen wird. Die Energie des Lichts wird dabei in eine andere Energieform umgewandelt, z. B. Wärme oder chemische Energie.
- Was passiert mit dem Licht?: Das Licht verschwindet (wird „verschluckt“), und seine Energie wird in der Materie gespeichert oder umgewandelt.
- Beispiele:
- Wasser absorbiert rotes Licht stärker als blaues Licht, was dazu führt, dass Wasser blau erscheint.
- Schwarze Oberflächen absorbieren fast das gesamte sichtbare Licht und wandeln es in Wärme um.
- Wichtig: Bei der Absorption wird das Licht „verbraucht“ und verschwindet aus dem sichtbaren Bereich.
| Eigenschaft | Streuung | Absorption |
| Was passiert? | Licht wird umgelenkt | Licht wird „verschluckt“ und in Energie umgewandelt |
| Licht bleibt erhalten? | Ja, es wird nur in eine andere Richtung gelenkt | Nein, es wird in der Materie „verbraucht“ |
| Energie des Lichts | Bleibt gleich | Wird in Wärme oder andere Energieformen umgewandelt |
| Beispiele | Blauer Himmel, Nebel, Wolken | Blaues Wasser, schwarze Oberflächen, Sonnenbrillen |
- Zusammenhang zwischen Streuung und Absorption
In der Realität treten Streuung und Absorption oft gleichzeitig auf. Zum Beispiel, wenn Licht durch Wasser oder die Atmosphäre geht, wird ein Teil des Lichts gestreut und ein anderer Teil absorbiert. Die Kombination dieser Effekte bestimmt, wie ein Material oder Medium für uns aussieht.
Absorption bei Wasser
Die Absorption von rotem Licht durch Wasser basiert auf den molekularen Eigenschaften des Wassermoleküls und dessen Schwingungsmoden. Es hängt mit den Bindungen im Wassermolekül, den Valenzelektronen und den quantenmechanischen Eigenschaften der Molekülschwingungen zusammen. Hier ist eine detaillierte Erklärung:
- Ursache der Absorption von rotem Licht
Die Absorption von Licht durch ein Molekül wie Wasser hängt von den Schwingungs- und Rotationsmoden der Molekülbindungen ab. Im Fall von Wasser:
- Wassermolekül (H₂O): Das Wassermolekül besteht aus zwei Wasserstoffatomen, die kovalent an ein Sauerstoffatom gebunden sind. Die O-H-Bindungen sind polar, da Sauerstoff elektronegativer ist als Wasserstoff. Dies führt zu einer ungleichen Verteilung der Elektronen und einem Dipolmoment.
- Schwingungsmoden: Die O-H-Bindungen im Wassermolekül können auf verschiedene Arten schwingen:
- Symmetrische Streckschwingung: Beide O-H-Bindungen dehnen sich gleichzeitig.
- Asymmetrische Streckschwingung: Eine O-H-Bindung dehnt sich, während die andere sich zusammenzieht.
- Beugeschwingung: Die Bindungswinkel zwischen den H-Atomen und dem O-Atom ändern sich.
Diese Schwingungen haben spezifische Energieniveaus, die durch die Quantenmechanik bestimmt werden. Die Energien dieser Schwingungen liegen im Infrarotbereich, aber sie haben auch schwache Obertöne (höhere Harmonische), die in den sichtbaren Bereich hineinreichen.
- Absorption von rotem Licht: Die Obertöne der Schwingungsmoden des Wassermoleküls überlappen mit den Wellenlängen des roten Lichts (ca. 620–750 nm). Das bedeutet, dass Wasser rotes Licht stärker absorbiert, während blaues Licht weniger absorbiert wird. Dies führt dazu, dass Wasser für das menschliche Auge blau erscheint.
- Molekulare Bindungen und Valenzelektronen
Die Absorption von Licht durch ein Molekül hängt von der Wechselwirkung zwischen dem elektromagnetischen Feld des Lichts und den Elektronen sowie den Bindungen im Molekül ab:
- Valenzelektronen: Die Valenzelektronen des Sauerstoffatoms und der Wasserstoffatome sind an den kovalenten Bindungen beteiligt. Diese Elektronen sind in den O-H-Bindungen lokalisiert und beeinflussen die Schwingungsmoden des Moleküls.
- Dipolmoment: Da das Wassermolekül ein permanentes Dipolmoment hat, kann es mit elektromagnetischen Wellen (wie Licht) interagieren. Die Schwingungen der O-H-Bindungen ändern das Dipolmoment des Moleküls, was es ermöglicht, Energie aus dem Licht aufzunehmen.
- Berechnung der Schwingungsfrequenzen: Die Schwingungsfrequenzen eines Moleküls können mit Hilfe der Quantenmechanik und der Moleküldynamik berechnet werden. Die Energie der Schwingungen hängt von der Masse der Atome und der Stärke der Bindungen ab. Die Schwingungsfrequenzen ( \nu ) können mit der Formel berechnet werden: [ \nu = \frac{1}{2\pi} \sqrt{\frac{k}{\mu}} ] wobei:
- ( k ) die Kraftkonstante der Bindung ist (eine Maßzahl für die Bindungsstärke),
- ( \mu ) die reduzierte Masse der beiden Atome ist.
Die Obertöne dieser Schwingungen (z. B. 2× oder 3× der Grundfrequenz) können in den sichtbaren Bereich hineinreichen und die Absorption von rotem Licht erklären.
Kann man die Absorption berechnen?
Ja, die Absorption von Licht durch Wasser kann theoretisch berechnet werden, indem man die Schwingungsmoden und die Übergangswahrscheinlichkeiten zwischen den Energieniveaus analysiert. Dies erfordert:
- Quantenmechanische Berechnungen: Die Energieniveaus der Schwingungen und die Übergangswahrscheinlichkeiten können mit der Schrödinger-Gleichung berechnet werden.
- Experimentelle Daten: Die Kraftkonstanten der O-H-Bindungen und die Massen der Atome sind experimentell bekannt und können in die Berechnungen einfließen.
- Spektrale Analyse: Die Absorptionsspektren von Wasser können gemessen und mit den theoretischen Vorhersagen verglichen werden.
Fazit
Die Absorption von rotem Licht durch Wasser ist auf die Schwingungsmoden der O-H-Bindungen zurückzuführen, die durch die molekularen Eigenschaften des Wassers bestimmt werden. Diese Schwingungen haben Obertöne, die in den sichtbaren Bereich hineinreichen und rotes Licht stärker absorbieren als blaues Licht. Die Berechnung dieser Absorption erfordert eine Kombination aus Quantenmechanik, Moleküldynamik und experimentellen Daten.
Ein Danke geht an ein LLM, dass mir meine richtungsweisenden Fragen zielführend und ausführlich, ohne ins Detail zu gehen, beantwortet hat.
Bitte eine App – nicht schon wieder!
Diese Leute in den Unternehmen. Checken es nicht, dass man nicht für jeden SCHEIß ne App braucht und schon gar nicht „noch eine“ installieren will. Wozu auch, wenn man nur mal eben was braucht?
Aktuelles Beispiel
Der Aufreger des Tages ist mal wieder die Versicherungskammer Bayern. Wow, wir sind ja so modern und in der Digitalisierung angekommen. Ich wollte nur mal, als PDF, einen Beleg einreichen. Via Web. Aber nein. Es ist ja viel „einfacher“, wenn man noch 7 Schritte dazwischen macht.
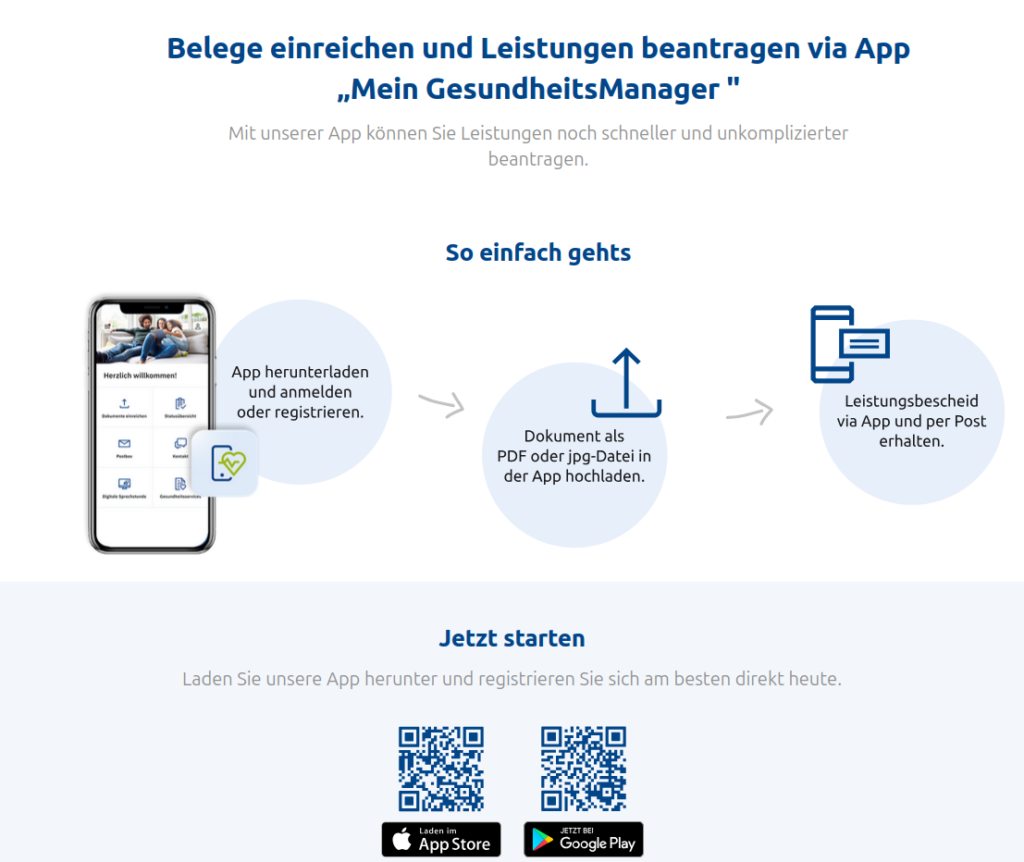
Man hätte auch einfach einen Upload-Button bauen können. Aber nein, man muss ja als App zum Kunden und bevorzugt ein schief und krummes Foto (eines Belegs) statt das Mehrseitige vom Scanner erzeugte PDF/A…..
Aber das Problem ist ja viel tiefgreifender (als nur die nächste App). Vielleicht ist es ja auch so, dass der Kunde behindert ist und mit Mobiltelefonen ganz schlecht umgehen kann, vieleicht gar keines hat? Vielleicht benötigt der Kunde einen PC mit Linux und speziellen Programmen, um überhaupt digitale Teilhabe zu haben…. das kann er dann aber gepflegt vergessen, denn VK-Bayern macht nur Post oder App. Da hat er dann Pech gehabt.
Aus Entwicklersicht ist das unverständlich, denn die APIs sind sowieso da. Der Authentifizierte Bereich auf der Webseite ebenfalls. Da wäre es ein Klacks, noch ein Paar Zugänglichkeits-GUIs hinzuzufügen.
Entscheiden Sie selbst! Ohja. Ich würde gerne per Upload auf der Webseite die Leistungen beantragen. Ach geht nicht? Ja warum soll ich dann selbst entscheiden?
Limit-Operations
Ein Ding, das ich bei C# schon immer und wieder vermisst habe (zumindest Damals[TM]) ist ein LimitTo.
Wie oft kommt es vor, dass man Parameterwerte oder irgendwelche Eingaben auf eine gewisse Spanne eingrenzen will. Daher habe ich mir schon lange mal die Klasse LimitOperations geschrieben, welche solche LimitTo-Erweiterungsmethoden enthält.
Aufgebaut auf IComparable klappt das mit jedem Datentyp.
Die Benutzung ist erwartungsgemäß eine neue Zuweisung. Der originäre Wert wird nicht angerührt. Geht also bestens mit Werttypen.
lvalue = lvalue.LimitTo(1,60);
Hier mal die von mir empfohlene Klasse. Ganz klassisch ohne UnitTests (uups)
Code
using System;
namespace WpfBib.Extensions
{
/// <summary>
/// Klasse stellt Erweiterungsmethoden bereit um an ordinalen Typen
/// Limits einzuhalten. Also "lass das nicht größer werden als..."
/// </summary>
/// <example>
/// int i = 43, j=i.LimitTo(2,44);
/// </example>
public static class LimitOperations
{
public static T LimitTo<T>(this T inValue, T lowerLimit, T upperLimit) where T : IComparable
{
if (inValue.CompareTo(lowerLimit) < 0)
return lowerLimit;
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
public static T LimitTo<T>(this T inValue, T upperLimit) where T : IComparable
{
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
public static double LimitTo_NoNan(this double inValue, double upperLimit)
{
if (double.IsNaN(upperLimit))
return inValue;
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
}
}
Amazon Pay ist auch Dreck
Wie ja generell Amazon Dreck ist und als normal gesinnter Mensch man diesem Laden aus dem Weg geht. Sowohl Ethisch (prekäre Arbeitsbedingungen, kein Steuerzahler), Machtpolitisch (Bezos ist zu reich und Geld ist Macht) als auch Kunden-technisch (kein Schwein redet mit einem). Schlicht: Man muss diesen Verein nicht unterstützen
Aufreger
Ich hab mal wieder einen Aufreger bekommen ohne danach gefragt zu haben. Dumm nur, dass ich mit dem Amazon-Konzern Geschäfte gemacht habe. Jetzt ärgere ich mich so sehr, dass ich mich hier auszukotzen muss.
Was ist passiert
Der Dreifachfail. Ich hatte was für einen Freund bestellt. Nicht bei Amazon, denn wer bei Trost ist, bestellt nicht bei Amazon. Also irgend ein Internethändler. Bezahlung ging umständlich, Klarna(türlichnicht) und Amazon Pay. Da ich dort seit Urzeiten noch meine IBAN drin hatte, dachte ich – der einfachste Weg. Lieferadresse eingegeben. Default Zahlungsmethode ausgewählt, klick, klick fertig.
Nö. Erstens ging das Paket dann doch an die Rechnungsadresse…. was zur Folge hatte, dass es nicht nur zu spät war, sondern auch noch 10€ mehr gekostet hat….. Dann kam mir aber noch Amazon Pay in die Quere. Die meinten dann irgendwie, ich solle doch Geld überweisen und dazu noch 3€ mehr wegen Rücklastschrift. Danke auch.
Rücklastschrift? Wieso das denn. In Amazon die Zahlungsmittel kontrolliert. Alles korrekte und gültige. Also WARUM? Unklar.
Ich erinnerte mich, dass die Standardauswahl nicht wirklich eine Bekannte Endziffer hatte (warum eigentlich immer nur Endziffern?). Aber ich dachte mir nichts weiter, denn ich hatte ja alle ungültigen Zahlungsmethoden längst rausgeworfen. Was also war passiert?
Natürlich war von Amazon Pay niemand zu sprechen. Ich bekam zwar mal Kontakt zu Amazon, aber nur um zu erfahren, dass Amazon Pay ja was komplett anderes ist als Amazon. Toll nur, dass ich in Amazon die Zahlungsmittel verwalte. Anscheinend mussten sie wegen irgendwelcher Steuervorteile ihre Bank nach Luxenburg auslagern – haha. Nur haben sie die Datenschnittstelle verpeilt. Der Default blieb, die Zahlungsmittel wurden aktualisiert.
Forderungen
Und jetzt, da sie…. die beiden Amazons da…. einen Fehler begangen hatten – ja mal eben von einer (in der Tat für alle Seiten) veralteten Zahlungsmethode abzubuchen. Da soll ich jetzt die Suppe auslöffeln, und ihre Rücklastschriftgebühr übernehmen.
Schlimmer noch: Ich habe jetzt UMSTÄNDE. Ich muss mich um SCHEIßE kümmern, derweil SIE der Zahlungsdienstleister sind, die sich darum kümmern sollte. Und ich soll noch mehr zahlen.
Dabei hatte ich alle Zahlungsmethoden gepflegt und korrekt,
Guten Tag! Wir haben Sie bereits mehrfach bezüglich der fehlgeschlagenen Zahlung per Lastschrift für Ihre Bestellung kontaktiert. Dabei haben wir auch die umgehende Zahlung angefordert, haben aber bisher immer noch keine Zahlung erhalten. Es kann bis zu 5 Geschäftstage dauern, bis die Bank die Zahlung verarbeitet hat und Ihr Kundenkonto aktualisiert wurde. Wenn Sie die Artikel bereits bezahlt oder zurückgesendet haben, können Sie diese Nachricht ignorieren. Falls wir innerhalb der nächsten 5 Geschäftstage keine Zahlung von Ihnen erhalten, übergeben wir den Vorgang an unsere Inkassoagentur (Riverty Services), die die Zahlung dann in unserem Auftrag von Ihnen einfordern wird. Bezahlen Sie bitte unverzüglich 33.48 EUR auf das folgende Konto, um Maßnahmen zu vermeiden: -- Empfänger: Amazon Payments Europe S.C.A. -- Bank: HSBC Trinkaus und Burkhardt -- IBAN: DE87300308801908262006 -- BIC: TUBDDEDDXXX -- Verwendungszweck: 34769184262122 Angaben zum Betrag: Bestellnummer Betrag Rücklastschriftsgrund ------------------------------------------------------------------------------------------ P02-7478620-0157327 EUR 30.48 Konto geschlossen Rücklastschriftentgelt EUR 3.00 ------------------------------------------------------------------------------------------ Gesamtbetrag EUR 33.48 Bestellte Artikel: Bestellnummer Bestelldatum Webseite ------------------------------------------------------------------------------------------ P02-7478620-0157327 15.04.2024 Xxxxxxxxxxxyyyy
Nein Danke
OK, so eine Behandlung brauche ich nicht. Ich mache einen NOCH größeren Bogen um Amazon. Tut es mir gleich und straft den Verein ab…
Resumé: Ehe die mich noch in der Schufa anschwärzen und ich keine Ruhe rein bekomme. Überweise ich ihnen jetzt Geld…. ist ja nur 3€ mehr. Grollgroll. Und nutze sie nie mehr. Vielleicht überweise ich auch mehr, damit sie was zurück überweisen müssen
Meine Firefox-Addons
Die Addons, ohne die ich keinen Firefox betreibe.
Firefox
Achja, ich benutze für fast alles Firefox. Ungoogled Chrome liegt daneben, falls mal irgendwas nicht so will – passiert leider immer wieder mal. Aja und Edge in allen Varianten lasse ich hinter mir liegen. Schaue ich quasi gar nicht an.
So fein diese OSS und Firefox-Geschichte auch ist, aber das Internet ist halt einfach schlecht und böse und möchte mit einigen Plugins gezähmt werden. Folgende Addons empfehle ich jedem, sich zu installieren und drin zu behalten:
Absolute Enable Right Click & Copy
Mit diesem Addon kann ich überall, da wo Webentwickler auch anderer Meinung sind, Kopieren und Einfügen nutzen. Wieso auch sollte es gefährlich sein, ein Passwort einzufügen. Wer verdammt will denn heute noch ohne Passwortmanager auskommen?
AdBlocker for YouTube™
Naja klar, wer schaut sich schon Werbung bei Youtube an. Also weg damit. Schneller wirds damit ohnehin.
DuckDuckGo Privacy Essentials
Privatsphäre und Datenschutz hoch. Dieses Addon von den Machern von DuckDuckGo blockiert die meisten Trackingcookies und Hosts. Ob’s was bringt, weiß ich nicht. Vielleicht gebe ich damit ja nur die Daten von Google zu Duck?! Aber fühle mich besser.
Everything Metric – Auto Unit Converter
Diese Erweiterung schreibt mir hinter alle im Text erkannten Imperialen Angaben noch eine verständliche, metrische Einheit dazu. Beispiel: 10 feet【𝟯 𝗺】mpg -> L/100 km
I don’t care about cookies
Cookiebanner sind nervig, supernervig. Vor allem, wenn sie verzögert nachgeladen werden. Da ist der Gesetzgeber auch irgendwie in die Scheiße getreten. Am Ende machen die Webseiten ohnehin, was sie wollen oder funktionieren nicht, wenn man nicht in alles einwilligt. Dieses Addon klickt automatisch immer und schnellstens auf Zustimmung. Denn im zweiten Schritt werden die Cookies dieser Sorte wieder automatisch gelöscht. Also nix gekonnt, weniger Nerv.
IPvFoo
Das braucht zwar nicht jeder, aber auf diese Weise kann ich als Interessierter sehen, wie viele der angesurften Webseiten zusätzliche Hosts ansteuern und ob die IPv6 oder noch IPv4 nutzen. Also ne Nerdsache.
KeePassXC-Browser
Weil ich ja einen Passwortmanager wie Keepass nutze (und Passwörter lokal + synchronisiert mit meiner nextcloud halt), brauche ich natürlich das Plugin, damit die Zugangsdaten im Browser landen.
LocalCDN
Auch wieder eine Kombi aus Datenschutz und Geschwindigkeit. Das Internet hat CDNs. Viele Webseiten nutzen diese Content Delivery Networks, um relativ nahe die Datenintensiven Downloads bereitzustellen. Nur: Damit kann man sich auch wieder überwachen lassen. Hier geht es eher um häufig genutzte .js wie bootstrap oder vue.js oder Fonts wie GoogleFonts oder fontawesome, die dann lokal in diesem Addon liegen. Somit spare ich wieder Zeit und Daten. Optional für manche.
Remove German Gender Language
Ja, Verunstaltungen der deutschen Sprache behindert den Lesefluss und ändert nichts an der Gesellschaft – es spaltet eher. Da man die Leute, die das machen jedoch nicht umerziehen kann, kann man zumindest die unlesbaren Textpassagen zurechtkemmen und von den meisten Auswüchsen sogenannter Gendersprache (die eigentlich Sexussprache heißen müsste) befreit. Sehr zu empfehlen.

uBlock Origin
Das Addon schlecht hin – alternativ zu AddBlockPlus. Es blockiert die wichtigsten der schlechten URLs und verhindert damit Tracking, lange ladezeiten und nervende Werbung. Natürlich nicht ganz, aber doch ganz schön. Unbedingt zu empfehlen, die Welt wird besser dadurch.
User-Agent Switcher and Manager
Der ist auch eher nerdig, aber manchmal muss man der Webseite halt vorgaukeln, dass man mit dem IE 6.0 unterwegs ist oder mit einem Mobilgerät drauf zugreift. Dann hilft dieser user agent switcher. Also eher optional, aber für mich gut.