Ich bin gerade verstärkt in meinem Lieblingstool opencode unterwegs. Zuletzt habe ich mich tiefer mit Subagents beschäftigt und wie man die parallel und sequentiell einsetzt. Und daraus gleich ein Video gemacht. Wer sich also vom Erklärbär Rob zeigen lassen will, wie man das effektiv einsetzt, immer zu: https://youtu.be/5BqGA7wuRAM
Kategorie: Softwareentwicklung
Wie ich OpenEMS zum laufen brachte
Hier mal eher ein Notitzblatt/Reminder, wie man OpenEMS zum laufen bekommt, da die Anleitung bei denen eher so mau ist. Oder wie beim Matheprof. „Das steht doch im Skript“… „ja, irgendwie 22 Seiten davor in einem Nebensatz im dritten Absatz links…. und ohne Beispiel“. Ja also hier mal was ich tat:
Aufbau
Zunächst zum Aufbau von OpenEMS. Es gibt die Teile:
- Edge
- Backend
- UI
- Zeitreihendatenbank/Influxdb
Man muss sich das so vorstellen, dass es mehrere Edge-EMS gibt. Das sind die lauffähigen Instanzen, die vor Ort sind und die eigentliche Arbeit des Messens und Steuerns machen. Die Rapportieren an das Backend (z.b. Messdaten und Stati)
Das Backend macht die Koordiation und Authentifizierung (hier Metadata genannt) und schreibt die Messdaten in eine Zeitreihendatenbank – hier verwendent: Influxdb
Zeitreihendatenbank/Influxdb: Die speichert die Messdaten und vergisst unwichtige Details.
UI: Die Grafishe Oberfläche. Das UI ist in node geschrieben und kann sowohl Edge als auch Backend betreuen. Typischerweise wird es zusammen mit ZeitDB und Backend auf einem Server im Internet erreichbar gehostet. In der Backendversion sieht man das Backend und alle verbunden Edge-Instanzen und kann dort „rüberwechseln“. Dabei mus keine eigene UI-Instanz per Edge laufen.
Deploy
Ich wollte ein docker deployment machen, damit man die Version schnell hochhauen kann. Ohne große Veränderung am Hostsystem. Und mit Renovate (Dienst) dann immer Up2Date ist. Einfach ein Redeploy machen.
Um nun InfluxDB, Backend und UI gemeinsam zu starten, hat sich diese docker-compose.yml-Datei bewährt. (docker label :develop kann durch :latest ersetzt werden)
services:
openems_backend:
image: openems/backend:develop
container_name: openems_backend
hostname: openems_backend
restart: unless-stopped
volumes:
- openems-backend-conf:/var/opt/openems/config:rw
- openems-backend-data:/var/opt/openems/data:rw
ports:
- 8079:8079 # Apache-Felix
- 8081:8081 # Edge-Websocket
- 8082:8082 # UI-Websocket
openems-ui:
image: openems/ui-backend:develop
container_name: openems_ui
hostname: openems_ui
restart: unless-stopped
volumes:
- openems-ui-conf:/etc/nginx:rw
- openems-ui-log:/var/log/nginx:rw
environment:
- UI_WEBSOCKET=ws://<publichost>:8082
ports:
- 1080:80
- 1443:443
openems_influxdb:
image: influxdb:alpine
container_name: openems_influxdb
hostname: openems_influxdb
restart: unless-stopped
volumes:
- openems-influxdb:/var/lib/influxdb2:rw
ports:
- 8086:8086
volumes:
openems-backend-conf:
openems-backend-data:
openems-ui-conf:
openems-ui-log:
openems-influxdb:
Natürlich wird man im Produktiven dann z.B. nginx als Reverse-Proxy davor hauen oder anderweitig TLS aktivieren.
Befehle:
# starten mit
docker compose up (-d)
# stoppen
docker compose down
# restart
docker compose restart
# status
docker ps
# backend logs anschauen
docker logs openems_backend -f
# shell
docker exec -it openems_backend bashEinrichten InfluxDB
Nachdem gestartet wurde, muss das Passwort und der API-Key (Notieren) von Influxdb gesetzt werden:
docker exec openems_influxdb influx setup \
--username openems \
--password WKeuIhl0deIJjrjoY62M \
--org openems.io \
--bucket openems \
--force
docker exec openems_influxdb influx auth listNun laufen einige Sachen
- Influxdb und Webobefläche: http://publichost:8086 mit openems:WKeuIhl0deIJjrjoY62M
- Backend ist erreichbar als Apache felix: http://publichost:8079/system/console mit admin:admin
- Backend hat einen Websocket exponiert: ws://publichost:8081
- UI ist erreichbar via http://publichost:8086/ ohne auth (irgendwas eingeben)
Das Problem ist erst mal, dass das Backend in einen Fehler läuft. Was man einem nicht sagt, ist, dass man eine metadata.conf-Datei braucht. Oder für den Test halt nicht braucht.WARN [end.metadata.file.MetadataFile] [Metadata.File] Unable to read file [/var/opt/openems/metadata.json]: /var/opt/openems/metadata.json (No such file or directory)
Das löst man, indem man beim Backend den Dummy-Metadata-Service konfiguriert: Gehe auf das Apache Felix des Backends (http://publichost:8079/system/console ) und kille Metadata.File und Hinzufüge Metadata.Dummy (keine Konfig erforderlich) Wenn es so aussieht, geht’s erst mal:
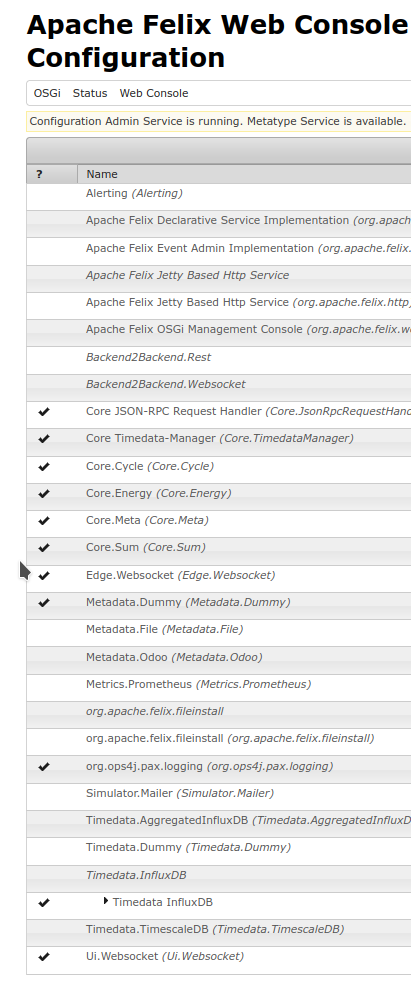
Timedata.InfluxDB sollte in etwa so aussehen:
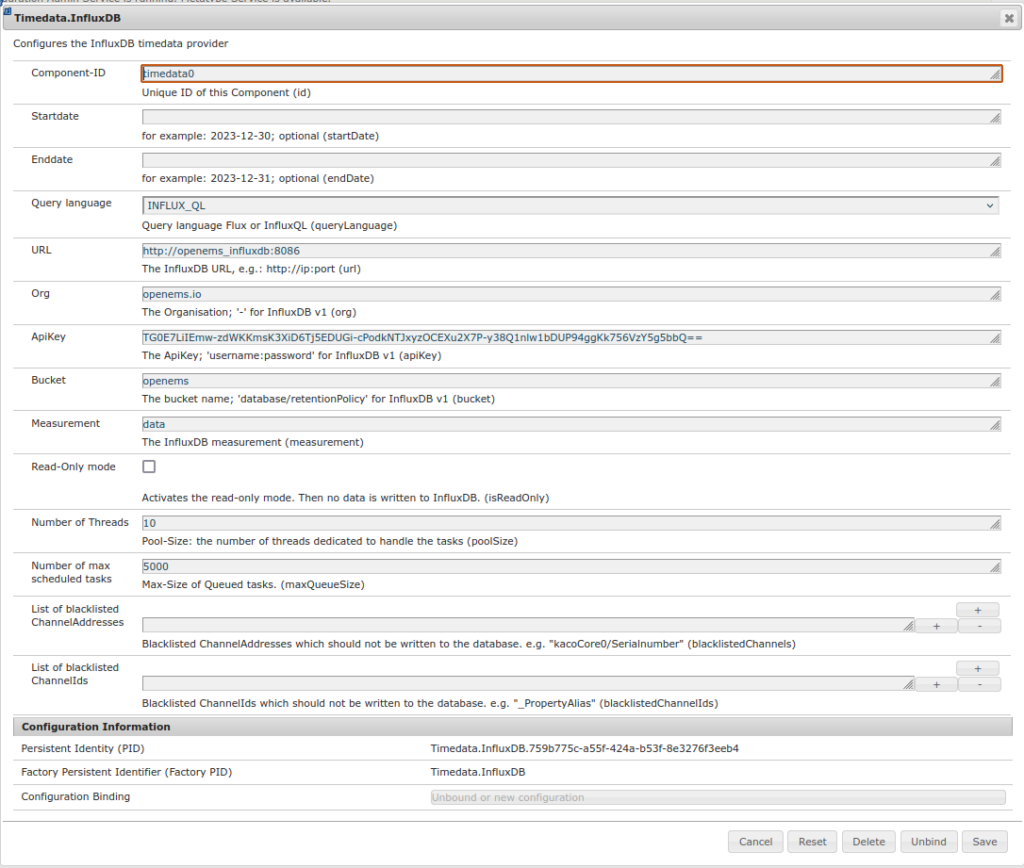
Der API-Key ist der, der weiter oben bei Einrichten InfluxDB ausgespuckt wurde. org und Bucket festlegen. Ansonsten kann man die influxdb Doker-Intern erreichen!
Zum vollständigen Glück fehlt noch ein wenig Konfig im Backend und eine Edge-Instanz und deren Konfig.
Edge
Um eine Edge-Instanz zu haben, habe ich mir ein Entwicklersystem eingerichtet und es lokal laufen lassen. Damit war ich dann zumindest mal auf einem anderen Host als da wo der Docker läuft. Macht es etwas realitätsnäher. Man kann die edge sicher auch als docker laufen lassen. Auf jeden Fall muss die irgendwie mit dem Backend verbunden werden und weiter Konfiguriert. Verbindung zum Backend gibt’s hier; nächstes Kapitel verweist auf weitere Konfigurationen, die in der Online-Doku sind, die man anwenden sollte auf der Edge.
Man geht also auf das Apache Felix der Edge-Instanz. Bei mir ist das (wegen Entwicklersystem) http://localhost:8080/system/console/configMgr PW: admin:admin
Hier Konfiguriere ich den Controller Api Backend wie folgt:
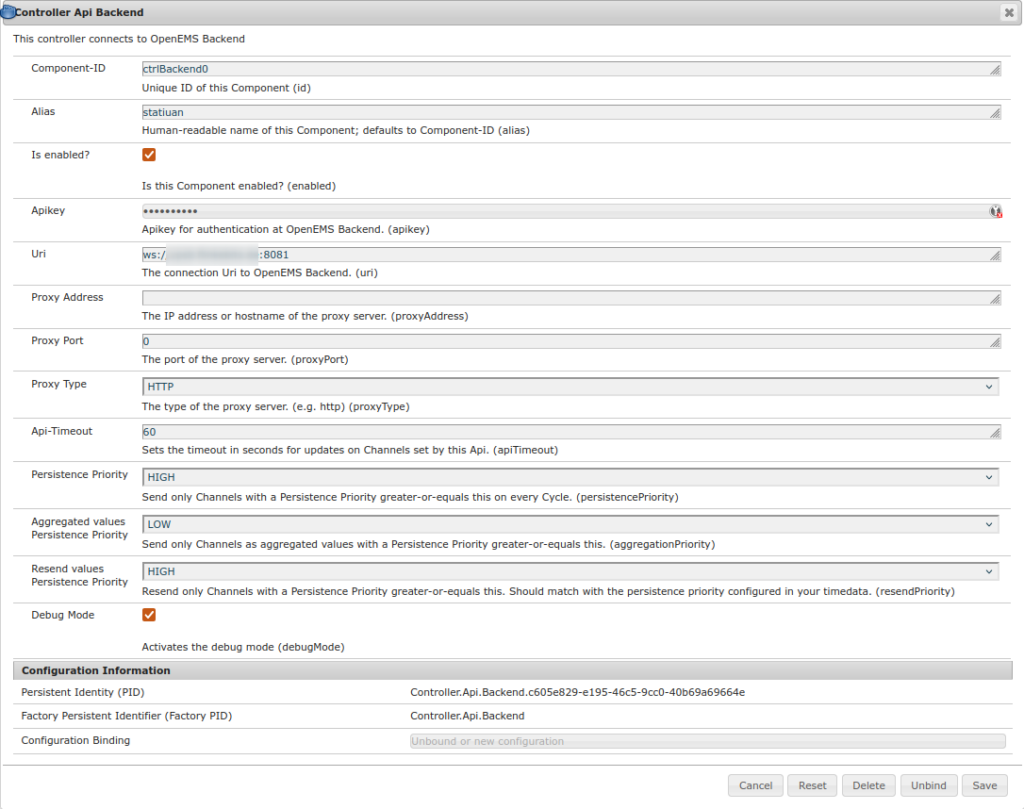
Wesentlich ist die WS-Url zu dem global auflösenden Namen des Backends. Wie durch Docker compose festgelegt ist es auf Port 8081. Da wir Metadata.Dummy einsetzen, ist der API-Key egal. Ebenso der alias.
Konfig des Backends und Edges
Edge braucht noch einige Komponenten, um ein wenig „was zu tun“.
Konfigurieren wie hier: https://openems.github.io/openems.io/openems/latest/gettingstarted.html#_configure_openems_edge
Test
Nun kann man auf die UI gehen: http://publichost:8086/ Nutzername ist wie gesagt egal (weil Metadata.Dummy) und dort sollte nun die Edge-Instanz auftauchen, die man gestartet hat.
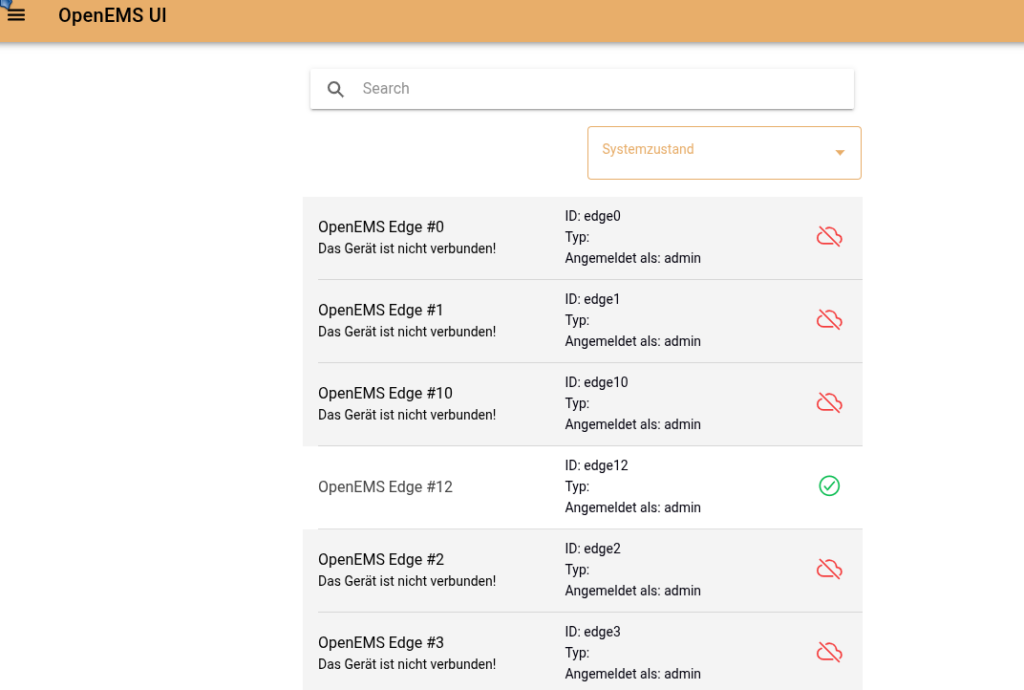
drinnen sieht es etwa so aus (je nach Simulation mehr)
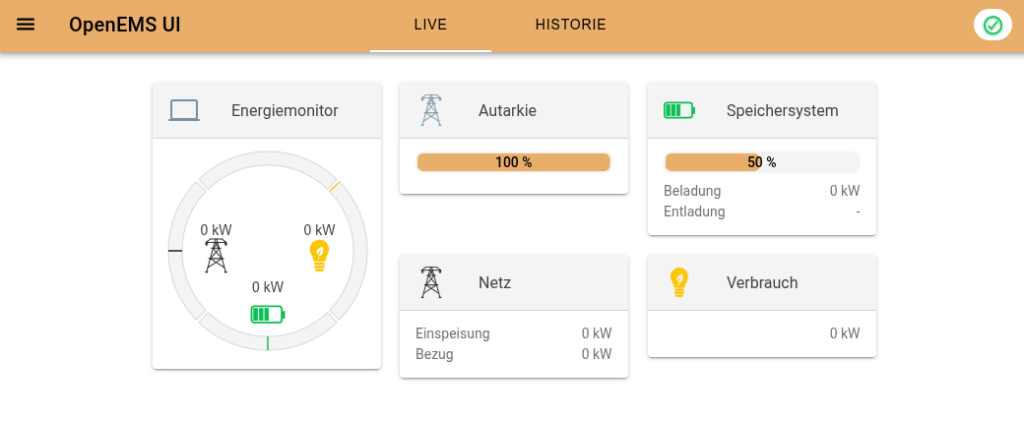
In die Historie kommt man auch (da man ja das Backend hat):
Wireguard auf einfach
Wireguard, dieses VPN kann einen ganz schön beschäftigen. Zunächst vermutet man die Funktionalität anders gelagert, ehe man später herausfindet, wie es ist und es korrekt macht. Um diesen Weg zu vereinfachen, habe ich mir gedacht, dass ich mal einige klärende Sätze los werde und meine paar Skripte dazu gebe, mit denen ich das Ganze Management ziemlich einfach gestaltet habe.
Wireguard das Wesen
Wireguard ist toll simpel und doch in der Konfiguration sehr komplex. Zumindest, wenn man unbedarft ran geht, versteht man erst mal nicht was eine gute Konfiguration ist und welche Randparameter einzuhalten sind.
Erkenntnis
Die Erkenntnisse dazu sind:
- Wireguard ist eine Punkt-zu-Punkt VPN-Verbindung. Das heißt, es werden keine Netze verbunden sondern immer nur zwei Interfaces miteinander.
- Daraus leitet sich die Folge ab, dass der Verkehr also über das einzurichtende Zwischennetz geroutet wird.
- Ein Paket wandert also von einem Netz durch den Forwarder in das VPN-Netz und auf der anderen Seite in das ferne Netz, wieder durch den Forwarder des VPN-Routers.
- Wireguard kann nur immer einen Gegner pro Interface und Port haben
- Man muss also viele kleine Netze anlegen und jeweils eigene Ports nutzen
- Es gibt Konfigs für Clients und für Server
- Die Schlüssel darin sind anitsymmetrisch darin verteilt (perfekt zur Automatisierung)
- Die IP-Adressen sind ebenfalls antisymmetrisch
- Andere Dinge sind gleich oder nur hier oder dort anzuwenden
Anwendungsfall
Ich beschränke mich hier auf den Anwendungsfall Netzkopplung mit einem zentralen Router. Sprich es gibt mehrere Clients und diese bringen entweder sich selbst oder zusätzlich ein ganzes Netz herein. Ab da funktioniert das Routing auch zwischen den Netzen (Voraussetzung sind allerdings gepflegte statische Routen auf dem Standardgateway der gekoppelten Netze = war immer so).
Skripte
Dieses wurde berücksichtigt, um die folgenden Skripte zu erstellen. Als einzigstes Ding muss man sich einen Namen ausdenken für den neuen Client. Und natürlich muss die dabei entstandene Client-Konfig auf den Client verbracht werden.
Die Skripte sind dazu gedacht, im /etc/wireguard-Verzeichnis zu residieren und dort lokal Änderungen zu machen und als root systemctl aufzurufen.
Als Infrastruktur kommt ein _-Verzeihnis mit. Darin sind die Vorlagedateien für die Server- und Client-Konfig drin mit Platzhalter. Das mk_-client.sh-Skript macht dann mit sed einen Such- und Ersetzenlauf. Weiterhin sind in diesem Verzeichnis .txt-Dateien, die die jeweils zuletzt vergebenene IP/Port enthält. Diese Dateien sind bei Bedarf/zu Beginn zu pflegen.
_/last-ip.txt
10.254.0.4Anpassen bei Bedarf – das 10er Netz scheint gut. Es wird immer 2 hochgezählt, da ja immer Point-to-Point zwei Adressen gebraucht werden.
_/last-port.txt
14264Hier wird der letzte Port gemerkt und weiter hochgezählt. alles uter 64k ist gut.
_/client.conf
[Interface]
# set address to next address
Address = :CLIENT_IP:/32
PrivateKey = :CLIENT_KEY:
#DNS = 8.8.8.8
[Peer]
PublicKey = :SERVER_PUB_KEY:
Endpoint = :SERVER_ADDRESS:::PORT:
PresharedKey = :PSK:
# Route only vpn trafic through vpn
AllowedIPs = 10.254.0.0/24, 192.168.88.0/24, 192.168.22.0/24
# Route ALL traffic through vpn
#AllowedIPs = 0.0.0.0/0
PersistentKeepalive = 21dsHier sind Platzhalter mit :PLH:-Notation drin, die beim Erzeugen ersetzt werden. Bei AllowedIPs kann der geneigte Admin all seine Netze hinzufügen. Da dieser Teil kopiert wird, müssen alle erstellten client.confs angepasst werden, wenn neue Netze hinzukommen. In diesem Fall sind es /24-Netze.
_/server.conf
[Interface]
Address = :SERVER_IP:/32
MTU = 1420
ListenPort = :PORT:
PrivateKey = :SERVER_KEY:
PostUp = /etc/wireguard/wg-iptables-updown.sh :IF_NAME: up
PostDown = /etc/wireguard/wg-iptables-updown.sh :IF_NAME: down
[Peer]
PublicKey = :CLIENT_PUB_KEY:
PresharedKey = :PSK:
AllowedIPs = :CLIENT_IP:/32Dies ist die Vorlage für neue Server-Konfigs. Interessant dabei, dass die eigene und Gegen-IP des VPN-Netzes /32-Adressen sind. Also genau je eine Adresse. Zudem ist hier der wg-iptables-updown.sh – Aufruf drin, der das Routing auf dem zentralen Router aktualisiert und entsprechende Forwarding-Regeln einfügt oder entfernt. Diese Datei ist auch mit dabei. Siehe hier:
wg-iptables-updown.sh
#!/bin/sh
iptables="/usr/sbin/iptables"
if [ -z "$1" ]; then
echo "No interface!"
echo "Usage: $0 [interface] [action]"
exit 0
fi
if [ -z "$2" ]; then
echo "No action!"
echo "Usage: $0 [interface] [action]"
echo "Actions:"
echo "* up"
echo "* down"
exit 0
elif [ "$2" = "up" ]; then
action="-A"
elif [ "$2" = "down" ]; then
action="-D"
else
echo "Unknown action!"
echo "Usage: $0 [interface] [action]"
echo "Actions:"
echo "* up"
echo "* down"
exit 0
fi
$iptables $action FORWARD -i $1 -j ACCEPT
$iptables $action FORWARD -o $1 -j ACCEPTHauptteil
Den Hauptteil bilden die zwei Skripte mk-client.sh und rm-client.sh
Damit wird ein neuer VPN-Entpunkt hinzugefügt bzw entfernt.
mk-client.sh
Einzig der Name für diese Verbindung wird als Parameter gebraucht. Es wird dafür ein öffentlicher und Privater Schlüssel und ein neues Geheimnis ausgewürfelt und in entsprechenden Dateien im ./clients/-Verzeichnis gespeichert. Von dort kann man die Dateien (eigentlich nur die .cofig) für den Client extrahieren und weitergeben. Die Server-.config wird im /etc/wireguard-Verzeichnis abgelegt und ist somit direkt verfügbar. Das wird auch gleich genutzt und wireguard damit konfiguriert. Sowohl die client- als auch die server-Konfig sind Kopien der Vorlagedateien. Die Platzhalter (wie z.B. Schlüssel und IPs) werden durch sed-Aufrufe ersetzt. So einfach.
Am Ende kommt noch eine Frage, ob man denn die Konfig gleich in systemd und beim Systemstart aktivieren möchte.
#!/bin/bash
VPN_HOST=vpn.flinkebits.de
if [ $# -eq 0 ]
then
echo "must pass a client name as an arg: mk-client.sh new-client"
else
umask 077
echo "Creating client config for: $1"
mkdir -p clients/$1
wg genkey | tee clients/$1/$1.priv | wg pubkey > clients/$1/$1.pub
CLIENT_KEY=$(cat clients/$1/$1.priv)
CLIENT_PUB_KEY=$(cat clients/$1/$1.pub)
infix=$(cat _/last-ip.txt | tr "." " " | awk '{print $4}')
ips="10.254.0."$(expr $infix + 1)
ipc="10.254.0."$(expr $infix + 2)
lastport=$(cat _/last-port.txt)
port=$(expr $lastport + 1)
wg genpsk > clients/$1/$1.psk
PSK=$(cat clients/$1/$1.psk)
wg genkey | tee clients/$1/server.priv | wg pubkey > clients/$1/server.pub
SERVER_KEY=$(cat clients/$1/server.priv)
SERVER_PUB_KEY=$(cat clients/$1/server.pub)
cat _/server.conf | sed -e 's|:PSK:|'"$PSK"'|' | sed -e 's/:SERVER_IP:/'"$ips"'/' | sed -e 's/:CLIENT_IP:/'"$ipc"'/' | sed -e 's|:SERVER_KEY:|'"$SERVER_KEY"'|' | sed -e 's|:CLIENT_PUB_KEY:|'"$CLIENT_PUB_KEY"'|' | sed -e 's|:PORT:|'"$port"'|' | sed -e 's|:IF_NAME:|'"wg-$1"'|' > wg-$1.conf
cat _/client.conf | sed -e 's|:PSK:|'"$PSK"'|' | sed -e 's/:CLIENT_IP:/'"$ipc"'/' | sed -e 's|:CLIENT_KEY:|'"$CLIENT_KEY"'|' | sed -e 's|:SERVER_PUB_KEY:|'"$SERVER_PUB_KEY"'|' | sed -e 's|:PORT:|'"$port"'|' | sed -e 's|:SERVER_ADDRESS:|'"$VPN_HOST"'|' > clients/$1/$1.conf
echo "Erzeuge in clients/$1 $1.priv, $1.pub, server.priv, server.pub"
echo "Erzeuge clients/$1/$1.conf"
echo "Erzeuge wg-$1.conf"
echo "Speichere zuletzt verwendete IP, Port: $ipc : $port"
echo $ipc > _/last-ip.txt
echo $port > _/last-port.txt
echo "Konfig fertig!"
read -p "Aktivieren von $1 in systemctl? (y/n) " yn
case $yn in
[yY] ) echo ok, we will proceed;
systemctl enable wg-quick@wg-$1.service
systemctl start wg-quick@wg-$1
;;
* ) echo exiting...;
exit;;
esac
firm-client.sh
Die rm-client macht es recht einfach. Fährt das interface ordentlich runter, entfernt es aus systemd und löscht die Dateien:
#!/bin/bash
if [ $# -eq 0 ]
then
echo "must pass a client name as an arg: $0 aclient"
else
wg-quick down wg-$1
systemctl stop wg-quick@wg-$1
systemctl disable wg-quick@wg-$1.service
rm -rfv "/etc/wireguard/clients/$1/"
rm -v "/etc/wireguard/wg-$1.conf"
fiGIT-Repo
Das Ganze könnt ihr auch in einem Git-Repo auf einmal herunterladen und in euer /etc/wireguard-Vz werfen. https://github.com/ChaosChemnitz/Wireguard-einfach
Lodgify per API abfragen
Seit einiger Zeit bin ich mit meiner Familie dabei, eine Ferienwohnung zu betreiben. Das ist eher aus der Not heraus geworden, denn die Gewerbeeinheit ließ sich sonst nicht vermieten. Ergo musste man halt mal selbst ran an die Sache.
Ich will hier gar nicht abschweifen in die Untiefen der Ferienwohnungen und deren Implikationen. Nur so viel: Ohne Buchungsportale geht heute quasi nix und wer nicht mindestens auf AirBnB und booking unterwegs ist, bekommt nichts vom Kuchen ab. Doch wie verwaltet man die mindestens zwei „Kanäle“? Man braucht einen „Channelmanager“. Davon gibt es in der echt recht korrupten Hoteleriebranche viele. Sie überbieten sich meist eher darin, ein möglichst großes Stück von deinem verdienten Geld mit abzugreifen – mit Prozenten etc.
Am Ende entscheidet man sich für irgendwas, was mit halbwegs normalen Kosten und Features wie dynamische Preise und (sowieso) Synchronisation der Kalender aufwartet. Bei uns ist das, wie auch immer, Lodgify geworden.
Aber jetzt kommts: Die bieten zwar einen Basistarif (der für uns die richtige Mischung ist), aber die echten Basisfeatures bieten sie halt da nicht an. Edit: Wundere mich gerade, warum überhaupt Kanäle buchbar angebunden sind??! Also was fehlt: Es gibt nicht mal eine absolute Basisübersicht über die Buchungen des aktuellen Monats und die Einnahmen. Dummerweise sollte man diese Daten haben, wenn man die lokalen Steuern bezahlen will. Aber dieses Feature gibt es auch nicht im Pro-Plan, sondern nur im Ultra-Plan. OKOK, ist wohl absolut ultra, dass ich mal so eine Übersicht als Tabelle benötige… nun ja.
Zum Glück aber gibt es ein Integrations-API. Damit konnte ich mit doch sehr überschaubarem Aufwand meine Buchungen abrufen. Hier mal mein Vorschlag, das in Python zu machen. Viel Spaß beim nachmachen:
Pythonimplementierung:
import requests
import pandas as pd
from datetime import datetime
# ggf installieren:
# pip install requests pandas openpyxl
# API-Konfiguration
API_KEY = "<bitte füllen>" # Ersetze mit deinem Lodgify API-Key
BASE_URL = "https://api.lodgify.com/v2/reservations/bookings"
# Zeitrahmen für die Abfrage (optional)
params = {
"size":100,
"includeExternal": True,
"stayFilter": "Historic",
"trash": False
}
# API-Anfrage mit korrektem X-ApiKey-Header
headers = {
"X-ApiKey": API_KEY,
"Accept-Language": "de",
"accept": "application/json"
}
try:
print("Starte API-Anfrage...")
response = requests.get(BASE_URL, headers=headers, params=params, timeout=10)
response.raise_for_status() # Löst HTTPError für 4xx/5xx Statuscodes aus
data = response.json()
# Prüfe, ob die Antwort die erwartete Struktur hat
if not isinstance(data, dict) or "items" not in data:
raise ValueError("Ungültige API-Antwort: JSON element 'items' nicht gefunden.")
except requests.exceptions.HTTPError as errh:
print(f"HTTP-Fehler: {errh}")
print(f"Statuscode: {response.status_code}")
print(f"Antwort: {response.text}")
exit(1)
except requests.exceptions.ConnectionError as errc:
print(f"Verbindungsfehler: {errc}")
exit(1)
except requests.exceptions.Timeout as errt:
print(f"Timeout-Fehler: {errt}")
exit(1)
except requests.exceptions.RequestException as err:
print(f"Anfragefehler: {err}")
exit(1)
except ValueError as ve:
print(f"Datenfehler: {ve}")
exit(1)
# Daten aufbereiten
bookings = []
for booking in data.get("items", []):
arrival = booking.get("arrival")
departure = booking.get("departure")
rooms = booking.get("rooms", [])
total_amount = booking.get("total_amount", 0)
guest = booking.get("guest")
# Anzahl der Tage berechnen
if arrival and departure:
try:
arrival_date = datetime.strptime(arrival, "%Y-%m-%d")
departure_date = datetime.strptime(departure, "%Y-%m-%d")
num_days = (departure_date - arrival_date).days
except ValueError:
num_days = 0
else:
num_days = 0
# Gast-Informationen aus dem ersten Zimmer extrahieren
adults = 0
children = 0
people = 0
if rooms:
guest_breakdown = rooms[0].get("guest_breakdown", {})
adults = guest_breakdown.get("adults", 0)
children = guest_breakdown.get("children", 0)
people = rooms[0].get("people", 0)
bookings.append({
"Buchungs-ID": booking.get("id"),
"Gastname": guest.get("name"),
"Startdatum": arrival,
"Enddatum": departure,
"Anzahl Tage": num_days,
"Anzahl Erwachsene": adults,
"Anzahl Kinder": children,
"Anzahl Personen": people,
"Einnahmen (€)": total_amount
})
# DataFrame erstellen
df = pd.DataFrame(bookings)
# In Excel-Datei speichern
output_file = "lodgify_buchungen.xlsx"
try:
df.to_excel(output_file, index=False, engine="openpyxl")
print(f"✅ Daten wurden erfolgreich in {output_file} gespeichert.")
except Exception as e:
print(f"❌ Fehler beim Speichern der Excel-Datei: {e}")
exit(1)Ergebnis ist eie XLS-Datei mit den Buchungen und Einnahmen
Bitte eine App – nicht schon wieder!
Diese Leute in den Unternehmen. Checken es nicht, dass man nicht für jeden SCHEIß ne App braucht und schon gar nicht „noch eine“ installieren will. Wozu auch, wenn man nur mal eben was braucht?
Aktuelles Beispiel
Der Aufreger des Tages ist mal wieder die Versicherungskammer Bayern. Wow, wir sind ja so modern und in der Digitalisierung angekommen. Ich wollte nur mal, als PDF, einen Beleg einreichen. Via Web. Aber nein. Es ist ja viel „einfacher“, wenn man noch 7 Schritte dazwischen macht.
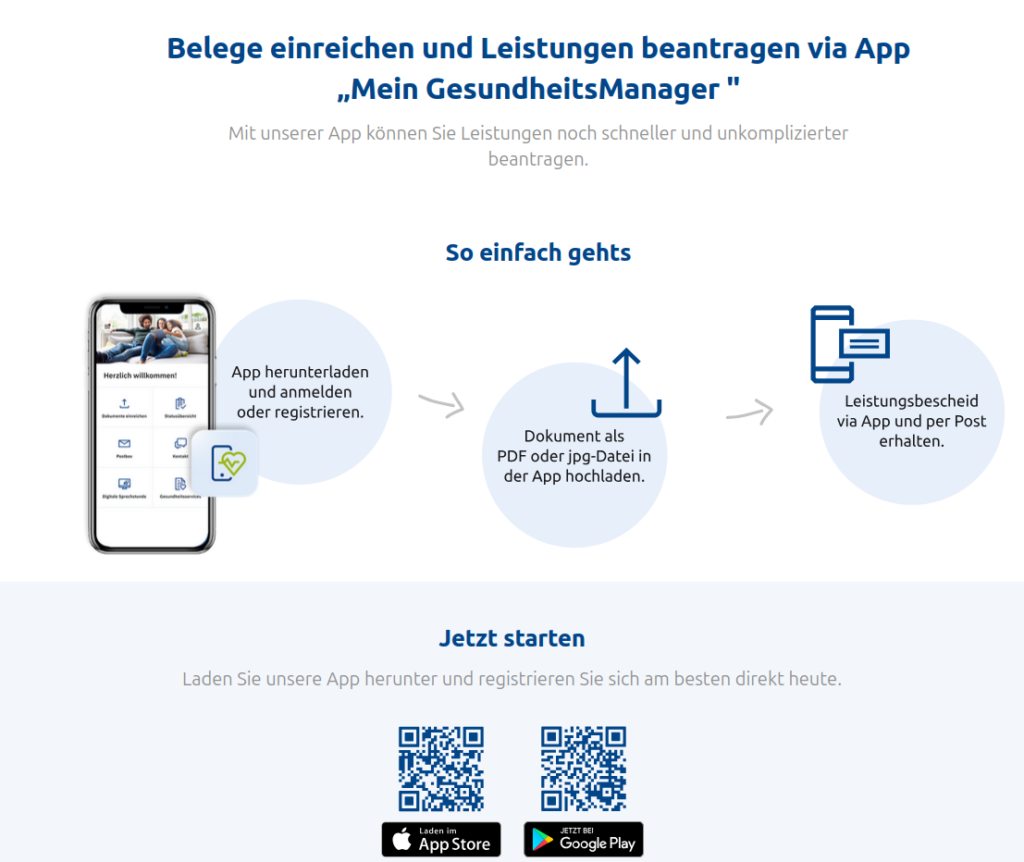
Man hätte auch einfach einen Upload-Button bauen können. Aber nein, man muss ja als App zum Kunden und bevorzugt ein schief und krummes Foto (eines Belegs) statt das Mehrseitige vom Scanner erzeugte PDF/A…..
Aber das Problem ist ja viel tiefgreifender (als nur die nächste App). Vielleicht ist es ja auch so, dass der Kunde behindert ist und mit Mobiltelefonen ganz schlecht umgehen kann, vieleicht gar keines hat? Vielleicht benötigt der Kunde einen PC mit Linux und speziellen Programmen, um überhaupt digitale Teilhabe zu haben…. das kann er dann aber gepflegt vergessen, denn VK-Bayern macht nur Post oder App. Da hat er dann Pech gehabt.
Aus Entwicklersicht ist das unverständlich, denn die APIs sind sowieso da. Der Authentifizierte Bereich auf der Webseite ebenfalls. Da wäre es ein Klacks, noch ein Paar Zugänglichkeits-GUIs hinzuzufügen.
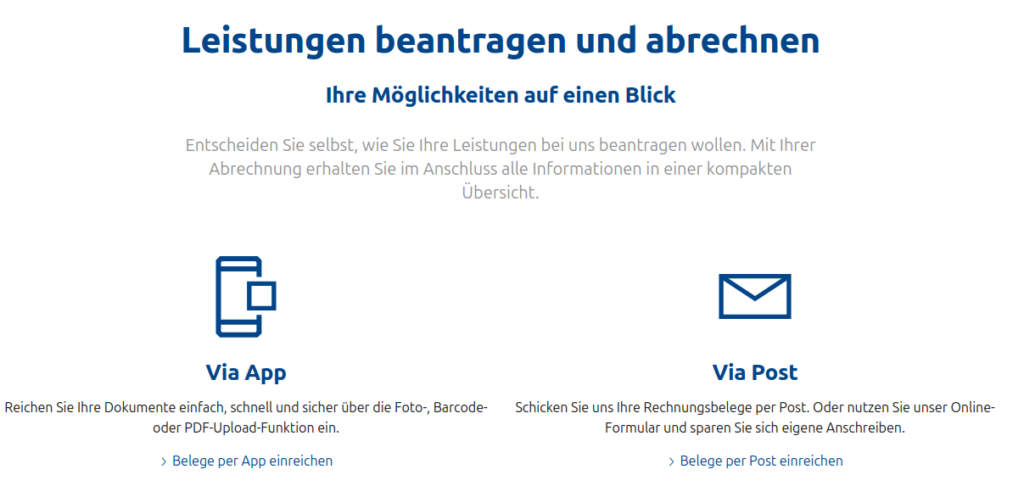
Entscheiden Sie selbst! Ohja. Ich würde gerne per Upload auf der Webseite die Leistungen beantragen. Ach geht nicht? Ja warum soll ich dann selbst entscheiden?
Limit-Operations
Ein Ding, das ich bei C# schon immer und wieder vermisst habe (zumindest Damals[TM]) ist ein LimitTo.
Wie oft kommt es vor, dass man Parameterwerte oder irgendwelche Eingaben auf eine gewisse Spanne eingrenzen will. Daher habe ich mir schon lange mal die Klasse LimitOperations geschrieben, welche solche LimitTo-Erweiterungsmethoden enthält.
Aufgebaut auf IComparable klappt das mit jedem Datentyp.
Die Benutzung ist erwartungsgemäß eine neue Zuweisung. Der originäre Wert wird nicht angerührt. Geht also bestens mit Werttypen.
lvalue = lvalue.LimitTo(1,60);
Hier mal die von mir empfohlene Klasse. Ganz klassisch ohne UnitTests (uups)
Code
using System;
namespace WpfBib.Extensions
{
/// <summary>
/// Klasse stellt Erweiterungsmethoden bereit um an ordinalen Typen
/// Limits einzuhalten. Also "lass das nicht größer werden als..."
/// </summary>
/// <example>
/// int i = 43, j=i.LimitTo(2,44);
/// </example>
public static class LimitOperations
{
public static T LimitTo<T>(this T inValue, T lowerLimit, T upperLimit) where T : IComparable
{
if (inValue.CompareTo(lowerLimit) < 0)
return lowerLimit;
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
public static T LimitTo<T>(this T inValue, T upperLimit) where T : IComparable
{
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
public static double LimitTo_NoNan(this double inValue, double upperLimit)
{
if (double.IsNaN(upperLimit))
return inValue;
if (inValue.CompareTo(upperLimit) > 0)
return upperLimit;
return inValue;
}
}
}
Mit EF N:M-Beziehungen pflegen
Letztens wieder in einem Projekt mit Entity Framework. Da habe ich wieder eine Erkenntnis erlangt, die ich hier zu teilen versuche.
Situation
Man stelle sich vor, die Software soll eine Tabelle mit einer Detailtabelle (n:m) bearbeiten. Als Beispiel nehmen wir Produkt und Laden. Zur Einnordung: Ein Produkt kann in vielen Läden geführt werden und ein Laden führt viele Produkte. Also klassisch n:m. Das Ganze soll mit Entity Framework umgesetzt werden. Als besondere Schwierigkeit hat Produkt keine Navigationseigenschaft für die Läden. Das mag EF nicht so sehr. Passieren kann das, wenn Produkt z.B. extern zugeliefert wird. Man also keinen Einfluss auf den Code hat.
Umsetzung:
Entitäten
public class Produkt
{
public Produkt(Guid id, string name, decimal preis)
{
Id = id;
Name = name;
Preis = preis;
}
public virtual Guid Id { get; set; }
public virtual string Name { get; set; }
public virtual decimal Preis { get; set; }
}
public class Laden
{
public Laden(Guid id, string name)
{
Id = id;
Name = name;
Produkte = new HashSet<Produkt>();
}
public Guid Id { get; }
public virtual string Name { get; set; }
public virtual string Inhaber { get; set; }
public virtual ICollection<Produkt> Produkte { get; set; }
}Laden verweist auf n Produkte, Produkte aber nicht auf Laden. Klassischerweise würde EF hier eine 1:n-Beziehung per Konvention machen. Daher ist Arbeit im Modelbuilder nötig. Hier also unser Datenkontext:
public class ErpDbContext : DbContext
{
public DbSet<Produkt> Produkts { get; set; }
public DbSet<Laden> Ladens { get; set; }
protected override void OnModelCreating(ModelBuilder builder)
{
base.OnModelCreating(builder);
builder.Entity<Produkt>(b =>
{
b.ToTable("Produkts");
b.ConfigureByConvention();
b.HasKey(x => x.Id);
b.Property(x => x.Name).HasColumnName(nameof(Produkt.Name)).IsRequired();
b.Property(x => x.Preis).HasColumnName(nameof(Produkt.Preis)).IsRequired();
});
builder.Entity<Laden>(b =>
{
b.ToTable("Ladens");
b.ConfigureByConvention();
b.HasKey(x => x.Id);
b.Property(x => x.Name).HasColumnName(nameof(Laden.Name)).IsRequired();
b.Property(x => x.Preis).HasColumnName(nameof(Laden.Inhaber));
b.HasMany<Produkt>(p => p.Produkte).WithMany("Laden").UsingEntity(j => j.ToTable("Produkt2Laden"));
});
}
}Hier werden die beiden Entitäten eingerichtet und auch die einseitige N:M-Beziehung von Laden auf Produkte. Entity Framework erzeugt nun im Hintergrund die nötige Zwischentabelle, die hier „Produkt2Laden“ genannt wird. Im optimalen Fall hätte man die Navigationsproperties auf beiden Seiten gesetzt, aber hier geht es ja genau darum, es nur einseitig zu haben.
Der Trick ist hier die Anweisung .HasMany(p => p.Produkte).WithMany("Ladens"). Hier wird es als n:m-Beziehung definiert. Normalerweise wäre Ladens eine Eigenschaft von Produkt. Aber die haben wir ja nicht. Bei WithMany() wird daher kein Lambda, sondern eine Zeichenkette verwendet. Mit Stringliteralen kann man wenigstens etwas faken. Es könnte also irgendwas dort stehen. Aus diesem Grund funktioniert auch nicht Alles komplett. Die Verwendung von .Include(), um die Detailtabelle mitzuladen, wird zum Problem. Es geht nicht unter allen Umständen. So z.B. bei diesem Versuch eines Delete:
public async Task DeleteProduktFromLadenAsync(Guid ladenId, Guid produktId)
{
Laden entitywithdteails = await this.Where(d => d.Id == ladenId).Include(i=>i.Produkte).FirstOrDefaultAsync();
Produkt detail = entitywithdteails.Teams.FirstOrDefault(z=>z.Id == orgId);
if( detail!=null )
{
entitywithdteails.Teams.Remove(detail);
}
}Dieser Versuch funktioniert nicht. Entity Framework gibt einem eine relativ nichtssagende Fehlermeldung. Auch wenn es nicht nötig ist, möchte EF da scheinbar einmal durch alle drei Relationen durch und wieder zurück. Da die „Rückreferenz“ also die ICollection<Produkt> Läden in Produkt fehlt, geht es per default nicht.
Nebenbei (wenn man also weiß, dass eine N:M-Beziehung über eine Zwischentabelle realisiert wird) ist es auch gar nicht nötig, zunächst auch nur eine der beiden Entitäten ([Laden,Produkt]) zu laden, um an den Beziehungen der beiden zu arbeiten. Umso mehr muss man sich um eine effiziente und zuverlässige Bearbeitung der Detailtabellendaten kümmern.
Coden
Ich bin dabei auf folgende beiden Implementierungen der Add/Remove-Operationen gekommen:
public async Task AddProdukteToLaden(Guid ladenId, Guid produktId)
{
ErpDbContext context = await GetDbContextAsync();
// fake element attachen und dann in die Collection rein.
var prod = new Produkt(produktId, null, null);
var laden = new Laden (ladenId, null, null);
context.Attach(laden);
// zeige EF, was passieren soll
laden.Produkte.Add(prod);
}public async Task DeleteProduktFromLadenAsync(Guid ladenId, Guid produktId)
{
var laden = new Laden(ladenId, string.Empty);
var produkt = new Produkt(produktId, string.Empty, 0);
// simuliere Zustand davor
laden.Produkte.Add(produkt);
var context = await GetDbContextAsync();
context.Attach(laden);
// zeige EF, was du willst
laden.Produkte.Remove(produkt);
}Der Trick besteht dabei darin, dass Entity Framework die Hauptentitäten gar nicht unbedingt holen muss. Es ist auch nicht wichtig, was in den Feldern steht. Einzig wichtig ist die Id des Datensatzes. Wenn man so eine Enität an den DB-Kontext per .Attach() anfügt, beginnt das Tracking von Entity Framework ab diesem Zeitpunkt. Werden keine anderen Eigenschaften/Felder verändert, hat es auch keine Updates zur Folge. Ergeo wird in diesem Fall nur das Add/Remove von der Detailkollektion mitgeschnitten und somit in die DB persisitiert.
Wir lernen also: Man braucht nicht die ganzen Entitäten zu laden um an Detailkollektionen Änderungen zu machen. Und: context.SaveChanges() nicht vergessen. In meinem Fall gab es ein Framework drumherum, welches alles in eine UnitOfWork einpackt und somit erfolgreiche Operationen automatisch persisitiert sind. Daher fehlt es bei meinen Beispielen.
Erfolgreiche Softwareentwicklung
In diesem Beitrag versuche ich eine lose Auflistung von Punkten zu bieten, die eine Softwareentwicklung erfolgreich machen. Klar ist: Alles kann nichts muss. Also ist es weder so, dass man alles einsetzen muss, noch ist der Erfolg bei Einsatz garantiert.
Kommen wir also zu meinen Empfehlungen. Vermutlich ist kollidieren sogar einige meiner Empfehlungen. Daher gilt: Nehmt Euch raus, was Euch gefällt und setzt es für Euch richtig um. Denn wie so oft im Leben gibt es mehr als nur schwarz und weiß. Viel Spaß.
- Einsatz eines Versionskontrollsystems (z.B. GIT)
- Einsatz von Entwicklungszweigen im VCS (Versionskontrollsystems). Branches.
- UnitTests: Für einzelne Klassen (Basisbausteine) bis hin zu Komponenten (Fertigbauteile) sollten UnitTests eingesetzt werden und bei CI/CD ausgeführt werden. UnitTests von Anfang an schreiben.
- Für Komponentenübergreifende Teile sollten Modultests gemacht werden. Testszenarien. GUI-Tests, Replay-Tests und bei Testreleases und sowieso bei Releases ausgeführt werden.
- Für die Gesamtanwendung sollte eine QA-Abteilung mit Menschen sich dran setzen. Die ganze Zeit und speziell zu Releases.
- Einrichtung einer CI/CD-Pipeline . UnitTests sollten dort ausgeführt werden, besser: Statische Analysen + Code-Style. Als Ergebnis wird ein Installer/Paket oder ein Deployter Container o.ä. erwartet. Ein Tester kann also gleich ran an den Speck!
- Release-Versionierung. Es kann für Regressionen wichtig sein, auf einen laufenden früheren Stand zurückzugehen. Also: „War das früher auch schon kaputt, oder ist das neu?“. Daher: Setups reproduzierbar machen (Installer, VMs, Container deployments etc.)
- Release-Management. Es braucht einen Plan, wie man von Release zu Release kommt und wie ältere gepflegt werden und welche Merkmale „gemerged“ werden.
- Ticketsystem einsetzen. Es ist unmöglich in einem Wust von Code und Information den Überblick zu behalten. Aufgaben müssen verwaltet werden. Tickets immer mit Commits im Versionskontrollsystem verknüpfen (wo sinnvoll).
- Logging einsetzen. Erfindet das Rad nicht neu! Nutzt Logging-Frameworks. So kann auch auf externe Server geloggt werden etc.
- Audit-Log. Je nach Anwendung frühzeitig einführen, denn später anflanschen ist doof. Es gibt immer wieder sicherheitsrelevante Dinge zu loggen -> Audit-Log
- Baut die Anwendung in Schichten auf. Es hat sich bewährt.
- ORM ist Pflicht. Die Datenschicht ist oft eine Relationale Datenbank. Vermeidet SQL-Zeug. Überbrückt die OO-ER-Lücke mit einem Object Relational Mapper (ORM) wie z.B. Entity Framework!
- Scheut Euch nicht, auch mal andere Konzepte auszuprobieren. Sie könnten für das zu lösende Problem eine einfachere, zuverlässigere Lösung parat haben. Genannt sei das Aktor-Modell oder Reactive oder Prolog-artige Horn-Klauseln.
- Baut Internationalisierung (i18n) von Anfang an ein. Das schärft gleich den Sinn, wann etwas lokalisiert dargestellt wird, und wann eine Darstellung kulturinvariant sein soll (bei Persistenz). Außerdem: Später hinzufügen ist wieder mal schlecht und teuer.
- Baut Barrierefreiheit (accessiblity, a11y) von Beginn an ein. Es ist inzwischen in manchen Ländern oder Bereichen (öffentliche Hand) Pflicht. Aber: Großes Thema, nicht einfach. Screenreader sollten aber an den Text kommen können.
- Setzt immer Unicode ein. Geht davon aus, dass die Anwender alle gültigen Zeichen der Welt einsetzen wollen und werden. Kodiert Dateien mit UTF-8-BOM.
- Lernt bei Developer Falsehoods und dem gigantischen Git-Repo über Falsehoods, was so die typischen Fehlannahmen sind und vermeidet sie. Schon gewusst: Vor+ Nachname sind eine Besonderheit, die es hier gibt.
- Bedenkt Sicherheit im Sinne von Security und setzt Verschlüsselung ein. Nutzt aber immer Bibliotheken und erfindet nichts selbst.
- Paarprogrammierung. Setzt das XP-Merkmal der Paar-Programmierung ein. Ein Junior kann von einem Senior so viel lernen und Umgekehrt. Oder Wissen aus verschiedenen Programmbereichen verteilen. Vorteil: Es gibt nicht mehr einzelne Koryphäen, da sich Wissen dupliziert. Man lernt Programmiertechniken und Prozesse und die Entwickler sind konzentrierter dabei und machen weniger Fehler, was den „doppelten Aufwand“ mehr als Wett macht.
- Nutze TDD – Test driven develoment. Nicht überall aber bei Kernkomponenten/Klassen empfohlen. Die dabei entstehenden UnitTests können gleich bleiben und in der CI-Pipeline verwendet werden.
- Coding-Standard. Entwickelt einen Formatierungsstandard und forciert ihn mit Programmen wie StyleCop.
- Code-Reviews. Macht z.b. alle 14 Tage ein öffentliches Review. Das ist ein unglaublich gutes Werkzeug, um Fehler zu finden und einander Einblick und Tricks zu vermitteln.
- Check-In mit Pull-Requets und 4-Augen-Prinzip. Nutzt die Mechanismen, die moderne Entwicklungsplattformen bieten. Bei Git gibt es einen zweistufigen Commit mit Code-Review. Nutzt das und lasst einen Check-In immer von einer anderen Person reviewen. Es hilft immens, Fehler von Beginn an zu vermeiden.
- Refaktorisieren. Mut zur Refaktorisierung. In der Regel kommt was besseres dabei raus. Schiefe Balken müssen gerade gerichtet werden. Nutzt Tools dazu.
- Kommentiert, aber auch nicht zu viel. Dokumentation veraltet schnell, Kommentare veralten auch. Daher Pflegt zumindest diese. Keine Kommentare ist auch falsch. Mittelweg! Bewährt hat sich, öffentliche Methoden zu kommentieren mit (ohoh) XML-Doc und die Klasse an sich. Dies gefällt mir insbesondere bei fremdem Code, wenn wieder „die nächste Klasse“ auftaucht, und man wieder sich fragt : „warum ist diese Klasse jetzt nötig, was verdammt soll ihre Aufgabe jetzt genau sein?“. Wer mir diese Frage gleich oben beantwortet (und die sollte recht konstant bleiben), der hat bei mir einen Stein im Brett! Sparam im Quellcode zu kommentieren ist auch keine gute Idee. Ich vergesse recht schnell, welche kranken und doch genialen Ideen ich da hatte.
- Nutzt schlaue Tools. Tools, die Euch das Leben einfacher machen und z.B. Code überprüfen, generieren oder automatisch umstrukturieren. Genannt sei hier z.B. Re-Sharper. Viele haben Angst vor der Automatik, aber sie ist deterministisch und wenn man es einmal gelernt hat, ist sie ein Segen. Denn sie denkt meist sogar an mehr, als man selbst. Dazu gehören auch Analysetools, wie z.B. der Nachfolger von FxCop oder LINTer. Sie analysieren Code auf typische Fehler und weisen Entwickler darauf hin.
- Automatisiert, wo es geht. Das ist DevOps. Alle dummen, manuellen Schritte sollten wenn möglich automatisch getriggert und ausgeführt werden.
Ich auf den Chemnitzer Linux-Tagen
Dort habe ich am Sonntag 18:00 den Vortrag ༺Unicode༻ – Eine Einführung Ꙭ gehalten. Hier zur Nachlese/Sicht:
https://chemnitzer.linux-tage.de/2021/de/programm/beitrag/168#video
Mit AvaloniaUI Enums in XAML zeigen
Es geht um das GUI-Framework AvaloniaUI. Und es geht darum, wie man in der darin üblichen XAML-Beschreibung Enum-Werte in z.B. eine Combobox hineinbekommt – ohne extra Code.
Es gibt gewisse Kritik an diesem Vorgehen vor allem aus dem Kreise der AvaloniaUI-Kernprogrammierer. Man möchte lieber für alles und immer View-Modelle (MVVM) verwenden. Zweifellos, das ist gut. Aber es gibt auch Gründe, es anders herum zu machen. Zum Beispiel, wenn man einfach nur schnell etwas zusammenstecken möchte. Oder gerade eben kein Viewmodell will.
Zur Lösung: Man möchte z.B. diese GUI darstellen, wobei in der Combobox die Items aus einem eigenen oder bekannten Enum stammen sollen und selektierbar sein sollen. Hier: Dock aus dem DockPanel.

In dieser kleinen Demo wird die Combobox durch den Enum Dock gefüllt und im Weiteren dieser Selektionswert an die Dock-Eigenschaft des kastanienfarbenen Rechtecks gebunden. De XAML oder aXAML-Code dazu sieht so aus:
<UserControl xmlns="https://github.com/avaloniaui"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:adb="https://flinkebits.de/avadevbox"
mc:Ignorable="d" d:DesignWidth="800" d:DesignHeight="450"
x:Class="AvaloniaControls.Demo.RangeSliderDemo">
<StackPanel>
<TextBlock>Aufzählungswerte von Dock:</TextBlock>
<ComboBox Name="cbdock" Width="240"
HorizontalAlignment="Left"
SelectedIndex="2" Margin="10,5,0,30"
Items="{Binding Source={adb:EnumBindingSource {x:Type Dock}}}"/>
<Border BorderThickness="3" BorderBrush="AliceBlue" Margin="10" Height="300">
<DockPanel HorizontalAlignment="Stretch" VerticalAlignment="Stretch" >
<Rectangle DockPanel.Dock="{Binding #cbdock.SelectedItem}"
Width="55"
Height="44"
Fill="Maroon" />
<Button IsEnabled="False" >Rest</Button>
</DockPanel>
</Border>
</StackPanel>
</UserControl>
Früher in WPF hat man dazu nette Verrenkungen mit ObjectValueProvider gemacht. Doch den gibt es unter Avalonia nicht mehr. Stattdessen greife ich hier auf eine Markupextension zurück: EnumBindingSource. Allerdings gibt es Markupextensions in AvaloniaUI auch nicht so wirklich. Auf jeden Fall gibt es keine Ableitung von MarkupExtension. Das Problem für AvaloniaUI ist, dass man eigentlich gleichzeitig von AvaloniaObject und MarkupExtension erben wöllte, aber natrülichin C# nur eine Klasse beerbt werden kann!
Die Lösung ist, dass die XAML-Komponente von AvaloniaUI die Klasse MarkupExtension vollständig ignoriert und bei Verwendungen wie Markupextensions einfach nach Klassen sucht, die lediglich von AvaloniaObject abgeleitet sind und eine von mehreren möglichen public ProvideValue()-Signaturen hat. Avalonia lässt hier verschiedene Rückgabewerte zu. Konkrete und object, sowie verschiedene Parameter. Somit lässt sich diese Extension so schreiben:
public class EnumBindingSource : AvaloniaObject /*: MarkupExtension*/
{
private Type _enumType;
public Type EnumType
{
get { return this._enumType; }
set
{
if (value != this._enumType)
{
if (null != value)
{
Type enumType = Nullable.GetUnderlyingType(value) ?? value;
if (!enumType.IsEnum)
throw new ArgumentException("Type must be for an Enum.");
}
this._enumType = value;
}
}
}
public EnumBindingSource() { }
public EnumBindingSource(Type enumType)
{
this.EnumType = enumType;
}
public Array ProvideValue(IServiceProvider serviceProvider)
{
if (null == this._enumType)
throw new InvalidOperationException("The EnumType must be specified.");
Type actualEnumType = Nullable.GetUnderlyingType(this._enumType) ?? this._enumType;
Array enumValues = Enum.GetValues(actualEnumType);
if (actualEnumType == this._enumType)
return enumValues;
Array tempArray = Array.CreateInstance(actualEnumType, enumValues.Length + 1);
enumValues.CopyTo(tempArray, 1);
return tempArray;
}
}
Das Ganze geht noch besser, denn man könnte auch noch die Attribute DescriptionAttribute auf den Aufzählungswerten auswerten und damit eine Lokalisierung anbieten. Das geht natürlich genau so, dass der SelectedValue vom Enum-Typ ist und die Anzeige in der Combobox der Description-Text ist.
Aber das überlasse ich einer Übung des Lesers. Es gibt genug WPF-Beispiele, die genau das tun.